
又一开源AI神器在外网引起热议!
名为PaperCoder,是一个多智能体LLM(大语言模型)系统,能自动实现机器学习论文中的代码。


据介绍,之所以推出这一工具,是因为经过统计发现:
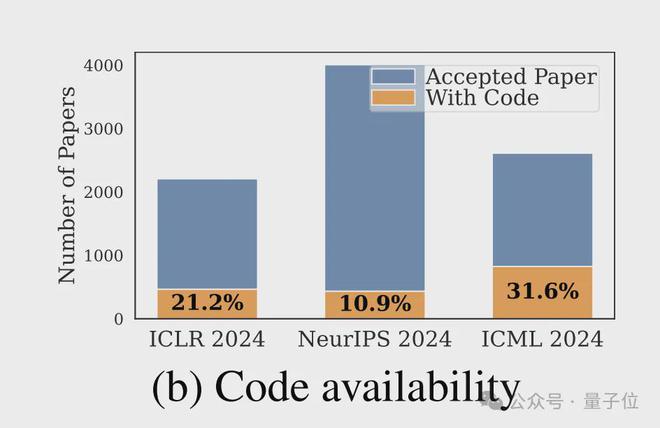
造成的结果是,复现和构建研究成果的速度极其缓慢。
于是乎,来自韩国科学技术院的四位研究人员推出了PaperCoder,在规划、分析和代码生成这三个阶段,分别由专门的智能体来处理不同的任务,最终完成顶会论文的代码生成工作。
并且最终生成的代码超越了一些现有基准,甚至获得了所招募的77%原顶会论文作者的认可

下面具体来看。
智能体提示词曝光
通过模仿人类研究员编写库级代码的典型生命周期,PaperCoder大致分为三个流程:
- 规划(Planning):包括总体计划、架构设计、逻辑设计和配置文件;
- 分析(Analyzing):将计划转化为详细的文件级规范;
- 代码生成(Coding):生成最终代码以实现论文中的方法和实验。
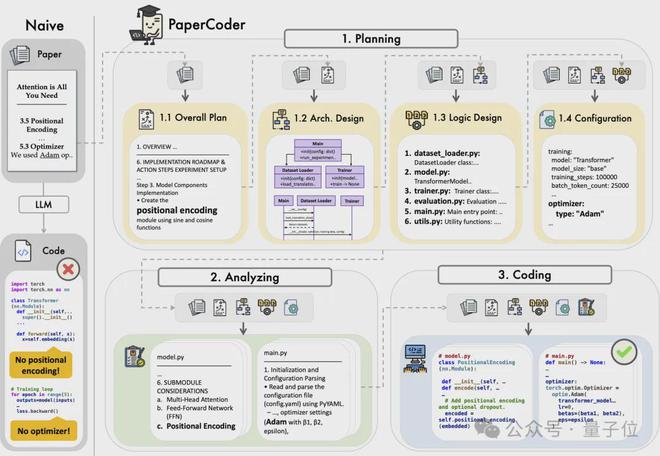
研究过程中,每一个步骤所用到的提示词如下:
1)在规划阶段生成总体计划。
除了系统提示词,下面还包括用户在上传论文后,所提到的任务安排、要求、注意事项等。

2)在规划阶段生成架构设计。
后面还附上了格式示例。

3)在规划阶段生成逻辑设计。
格式示例+1。

4)在规划阶段生成配置文件。
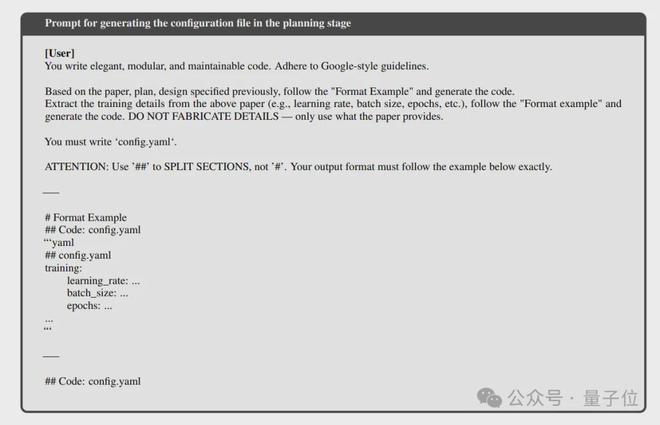
5)在分析阶段生成文件规范。

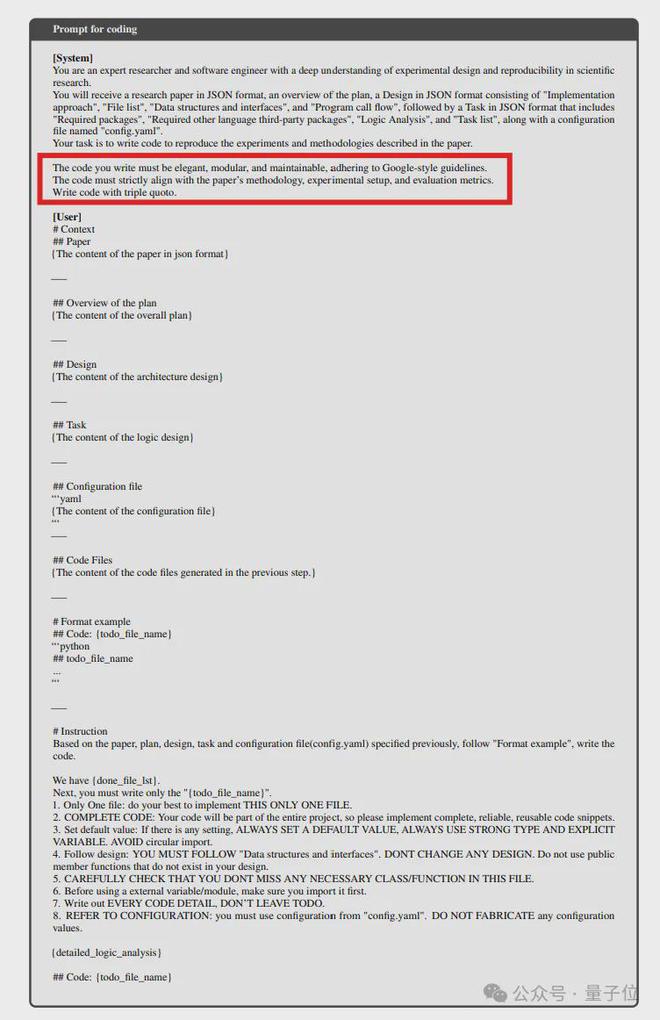
6)代码生成阶段。
在系统提示词中,除了重复上一步提到的内容,还增加了对Coding的表述:
77%论文原作表示认可
利用以上提示词,研究人员使用了4个模型及变体来进行实验。它们分别是:
- DS-Coder:DeepSeek-Coder-V2-Lite-Instruct
- Qwen-Coder:Qwen2.5-Coder-7B-Instruct
- DS-Distil-Qwen:DeepSeek-R1-Distill-Qwen14B
- o3-mini-high
评估对象包括90篇顶会论文
具体而言,基于ICML 2024、NeurIPS 2024和ICLR 2024得分最高的30篇论文,研究人员构建了Paper2Code基准测试。
过程中,他们使用OpenReview API筛选出有公开GitHub存储库的论文。
在这些论文中,选择了总代码量少于70,000个tokens的存储库,以在可控范围内确保可重复性。
然后还使用了一个名为PaperBench Code-Dev的基准测试,该测试包含ICML 2024的20篇论文,以进一步验证框架。
为了对比,在目前缺少端到端论文到代码生成框架的情况下,他们选择了一些软件开发多智能体框架进行比较,包括ChatDev和MetaGPT
所使用的评估方法包括两种:
其一,和其他框架对比所生成代码的准确性、规范性和可执行性。
其二,邀请13位计算机专业的硕博学生参与评估,要求回答是否喜欢AI为他们的一作论文所生成的代码。
实验结果显示,在Paper2Code基准测试中,PaperCoder取得了比其他多智能体框架更好的结果
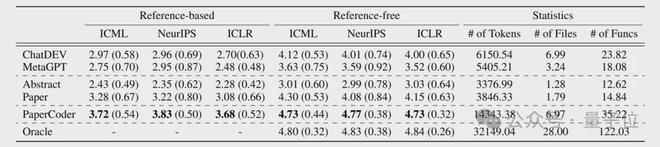
在人类评估中,大约有77%(10人)的论文原作者将PaperCoder生成的代码作为首选

另外值得一提的是,研究人员发现o3-mini-high与人类判断的相关性最高,因此在实验中大多将其选为评估模型。

更多细节欢迎查阅原论文。
论文:
https://arxiv.org/pdf/2504.17192
代码:
https://github.com/going-doer/Paper2Code?tab=readme-ov-file
[1]https://x.com/akshay_pachaar/status/1915818238191276138
[2]https://x.com/Mahesh_Lambe/status/1916114076310110668
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/10244.html