
新架构选择用KAN做3D感知,点云分析有了新SOTA!


来自哈尔滨工业大学(深圳)和宾夕法尼亚大学的联合团队最近推出了一种基于Kolmogorov-Arnold Networks(KANs)的3D感知解决方案——PointKAN,在处理点云数据的下游任务上展现出巨大的潜力。
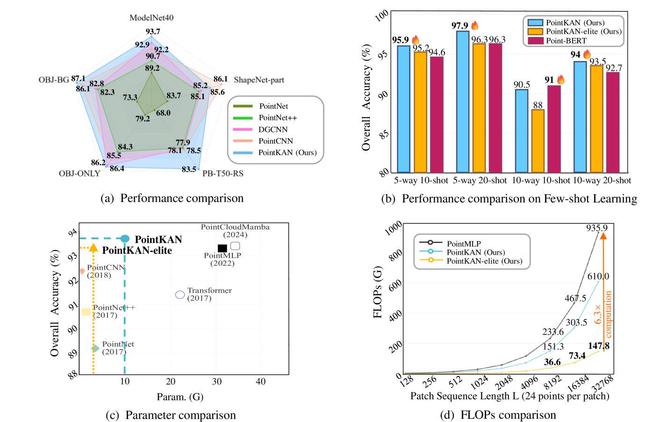
PointKAN与同类产品的比较
替代传统的MLP方案,PointKAN具有更强的学习复杂几何特征的能力。
此外团队还提出PointKAN-elite版本,使用Efficient-KANs结构,在保持准确率的同时显着降低参数量。

以下是更多详细内容介绍。
为什么要选择KANs
当前多层感知机(MLPs)凭借其高效的特征学习机制,已成为点云分析的基础架构组件。
然而在处理点云复杂几何结构时,MLP的固定激活函数难以有效捕捉局部几何特征,同时存在参数量冗余大、模型效率低下的问题。
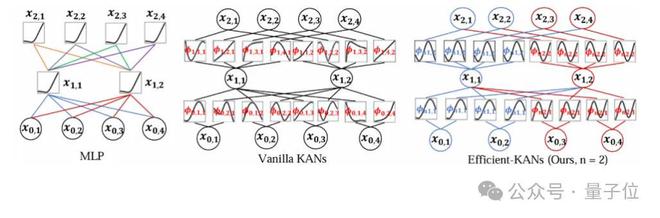
而KANs是以Kolmogorov-Arnold表示定理(KART)作为数学依据的一种新颖的神经网络架构,与多层感知机(MLP)结构的最大区别是KANs使用可学习函数替代固定激活函数。
KANs使用一维B样条函数作为基函数通过相加和复合运算实现高维复杂函数,为函数拟合提供了一个灵活且可解释的框架。
目前,KANs已初步应用于计算机视觉和医学成像等领域,展现出了有效性和通用性,但在点云分析领域中基于KANs的模型拥有巨大潜力尚未开发。
因此,探索在点云分析任务中有效整合KANs与现有模型的方法,仍是一个重要且有前景的研究方向。
PointKAN框架解析
PointKAN的整体流程如下图所示。
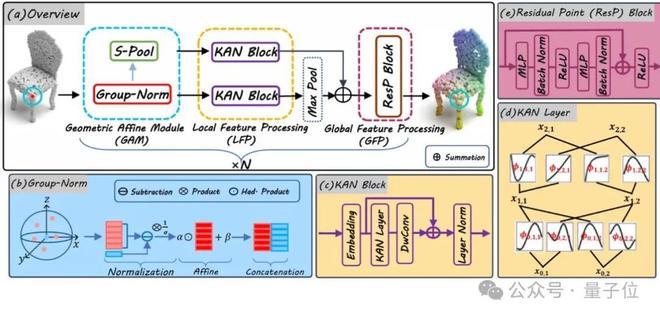
相比于MLPs,尽管KANs具有更强的高维函数逼近能力和更高的参数效率,但将其适配到3D点云上并非易事。
一方面,KANs的样条激活函数通过离散节点逼近单变量函数,很难充分捕捉局部点云的几何特征,限制了其学习细节特征的能力。
另一方面,每一维输入的激活函数需要存储多个参数,对于大规模网络,KANs的内存需求可能成为瓶颈,并且KANs中使用的B样条函数对于现代硬件上的并行计算未进行优化,导致推理速度较慢。
为了解决上述问题,研究团队提出了PointKAN,其特点是包含几何仿射模块和并行结构的局部特征提取模块,以及KANs的高效版本Efficient-KANs来减少内存占用并加快训练和推理速度。
Geometric Affine Module
为了在后续的局部特征提取阶段能得到更加丰富的信息,在这个模块中包含两个部分Group-Norm和S-Pool。
Group-Norm对分组内特征进行归一化、仿射变换和组中心特征传播,整个过程表达如下:
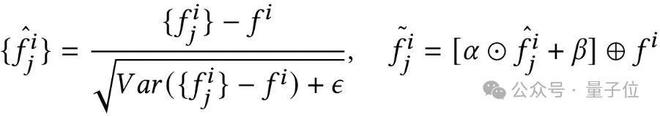
S-Pool用于对各组特征进行聚合,作为后续模块的输入,对各组点云进行全局信息的补充,考虑到最大池化会导致信息丢失,而S-Pool则最大限度保留组内各点特征信息,数学形式如下:
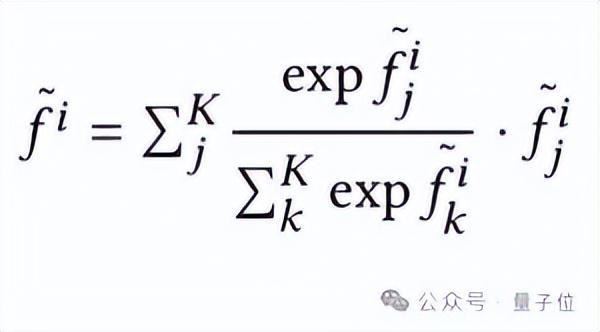
Local Feature Processing
对Geometric Affine Module的两部分输出在Local Feature Progress(LFP)中分别使用KAN Block进行并行处理。
在KAN Block中,团队在KAN Layer 后加上深度卷积(DwConv)操作来协助KANs在高维通道信息上学习到丰富的特征表示,整个过程可以被表示为:
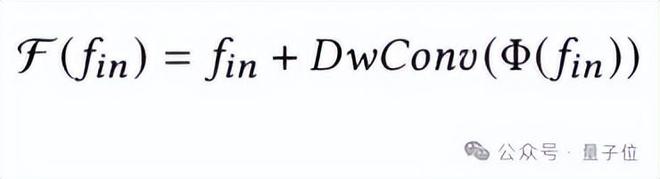
共享的LFP旨在从分组点云中学习到局部特征,在经过最大池化后与从各组中心点云学习到的全局信息相加,使得各组点云最终输出的聚合特征更加丰富。
Global Feature Processing
Global Feature Progress(GFP)由Residual Point(Resp)Block组成,用于提取深度聚合特征。
由于结构中只包含前馈MLP,使得可以在GFP中添加多个重复Residual Point(Resp)Block,整个模型仍然能高效运行。
总的来说,代替使用复杂的局部几何提取结构,PointKAN的一个阶段由Geometric Affine Module、Local Feature Processing和Global Feature Processing三部分组成,通过重复的四个阶段来构造一个层次化处理点云的深度网络。
Efficient-KANs结构
KANs中的激活函数是由B样条函数生成的,而B样条函数需要递归计算,这并不适合现代GPU的并行计算架构。
在参数量和计算效率上,每个输入-输出对都有不同的参数和基函数,那么随着KANs中隐藏层宽度的增加,参数量呈指数增长,这也导致了巨大的计算开销和可扩展性问题。
Efficient-KANs很好的解决了这些问题,首先使用有理函数代替B样条函数作为KANs中的基函数,激活函数如下所示:
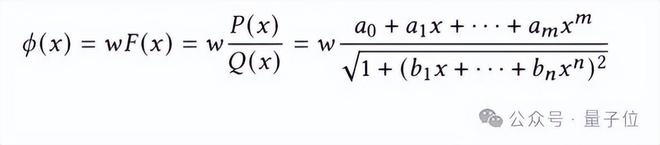
其中的参数通过反向传播进行训练。有理函数计算过程简单,非常适合并行计算,提高了模型的计算效率。
另外Efficient-KANs对输入通道进行分组,在组内进行参数共享,来减少参数量和计算量。
下图展示了Efficient-KANs、原始KANs和标准MLP之间的区别。
实验结果
分类任务
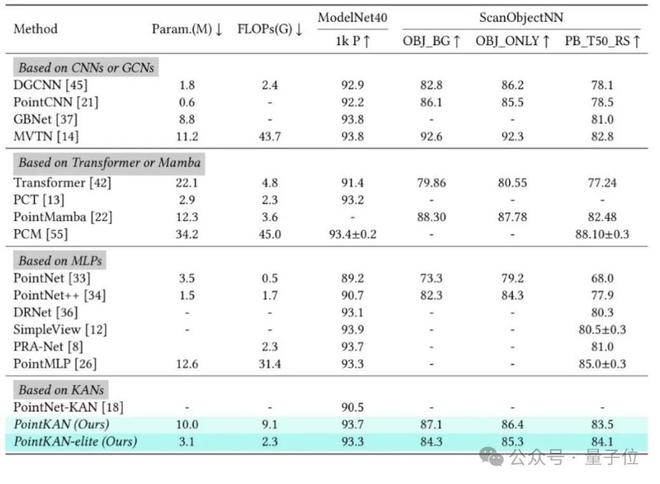
在ModelNet40和ScanObjectNN数据集上进行实验。
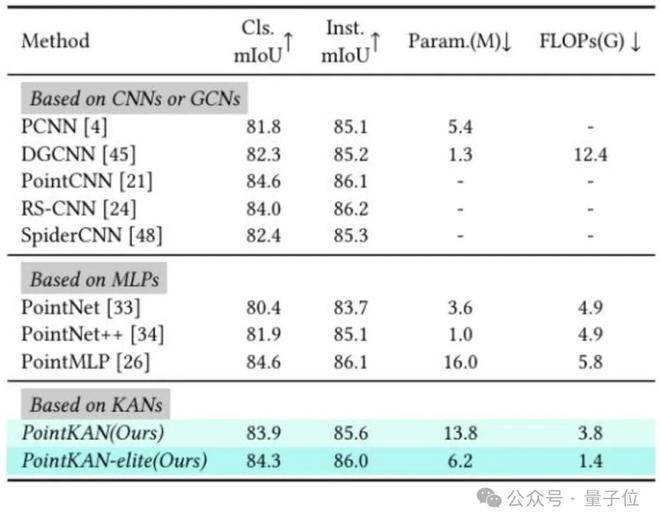
部分分割任务
在ShapeNetPart数据集上进行实验。
小样本学习
在ModelNet40数据集上采用“n-way, m-shot”范式进行实验。
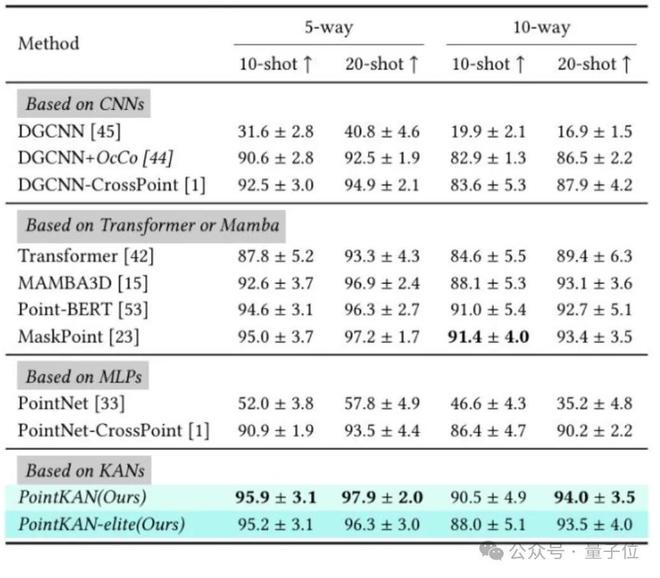
实验结果表明,PointKAN以及PointKAN-elite在各个下游任务上相比于基于MLPs的点云分析架构都有出色的表现,特别是在小样本学习任务上,体现了KANs具有极强的泛化能力和知识迁移能力,更重要的是参数量和FLOPs都有明显的下降。
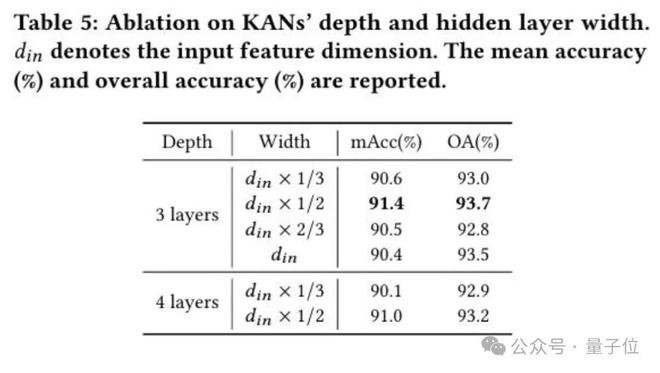
此外消融实验如下图所示:
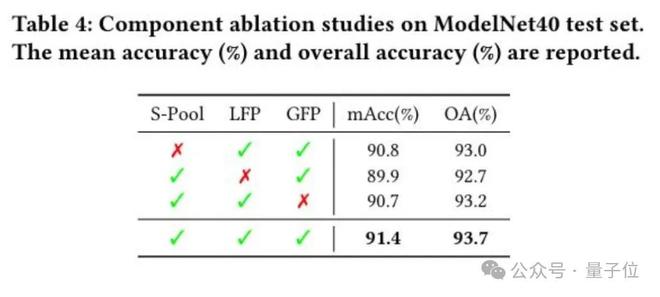
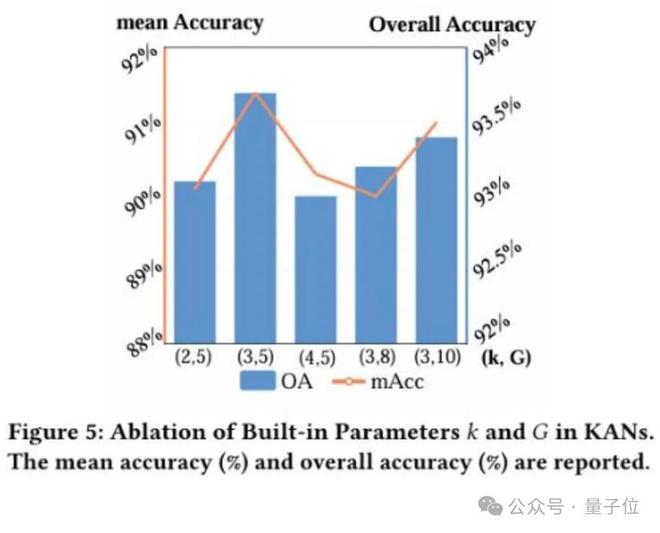
总结
在本文中,研究人员提出了PointKAN,一种基于Kolmogorov-Arnold网络(KANs)的高效点云分析架构。
相较于基于多层感知机(MLPs)的PointMLP架构,PointKAN在多项任务中均表现出更优性能,充分验证了KANs在提取局部细节特征方面的强大能力。
此外,研究团队还提出了更高效的轻量化版本PointKAN-elite,该版本在保持精度的同时,进一步降低了参数量与计算成本。
团队期待PointKAN能够推动KANs在点云分析领域的应用,充分发挥其相较于MLPs的独特优势。
论文链接:https://arxiv.org/abs/2504.13593
代码链接:https://github.com/Shiyan-cps/PointKAN-pytorch
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/14987.html