
推理大模型开卷新方向,阿里开源长文本深度思考模型QwenLong-L1,登上HuggingFace今日热门论文第二。


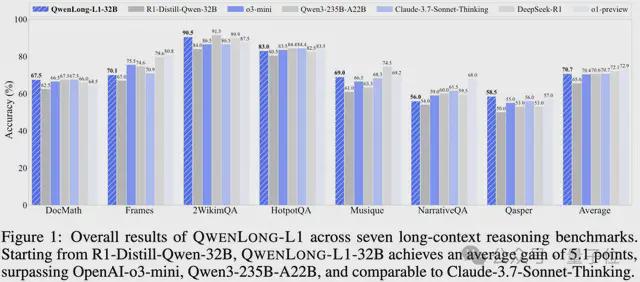
其32B参数版本超过OpenAI-o3-mini、Qwen3-235B-A22B等,取得与Claude-3.7-Sonnet-Thingking相当的性能。
除测评分数外,论文中还详细展示了一个金融文档推理的案例。传统模型容易被无关细节误导,而QwenLong-L1通过回溯和验证机制过滤干扰信息,正确整合关键数据。
任务要求:根据文档回答问题“将优先票据的发行成本与第一年的利息支出合并计算,总资本成本是多少?”
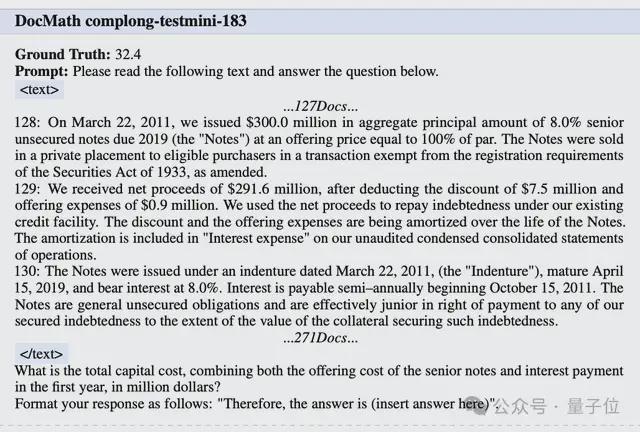
首先出场的基础模型DeepSeek-R1-Distill-Qwen-14B被文档中“自2011年10月15日起每半年支付一次利息”误导,根据不相关的时间和财务信息,错误计算了第一年的利息支付。

接下来,经过额外SFT的版本仍然未能解决这个问题。
它在对不相关文档进行过度分析的循环中自我怀疑,最终尽了最大生成限制(10000 tokens),却没有给出最终答案。

相比之下,虽然QwenLong-L1-14B最初也表现出类似的分心,但它很快进行了有效的自我反思。通过及时验证和回溯,成功过滤掉了不相关的细节,得出了正确答案。

那么,QwenLong-L1是如何做到的?
渐进式上下文扩展
首先,现有推理模型在面对长文本(如几万字甚至更长)时遇到什么问题?
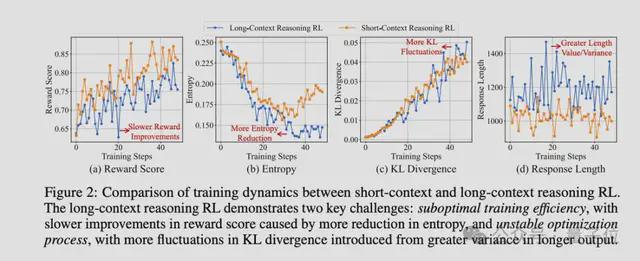
Qwen团队通过对比实验发现,长文本推理的强化学习训练存在两个“硬伤”:
一是训练效率低,传统强化学习(RL)方法在长文本中容易陷入局部最优,奖励收敛慢,限制了策略优化时的探索行为。
二是优化过程不稳定,长文本任务的输出长度更高、输入长度分布不均匀,导致策略更新时的方差被放大,训练过程中参数更新不稳定(如KL散度坐过山车)。
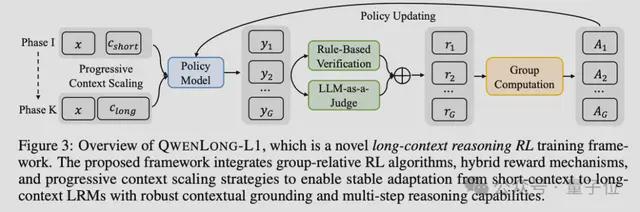
为此团队提出QwenLong-L1训练框架,核心是通过渐进式上下文扩展让模型逐步适应长文本推理。训练过程分为两阶段:
预热监督微调(Warm-Up Supervised Fine-Tuning)
在开始强化学习之前,先用高质量的演示数据进行监督微调,让模型先具备基本的长文本理解能力、推理链生成能力和答案提取能力。
团队从DeepSeek-R1蒸馏了5.3K个高质量的问题-文档-答案三元组,确保模型有个稳定的起点。实验结果显示,这个”热身”阶段对后续的强化学习训练至关重要。

课程引导的分阶段强化学习(Curriculum-Guided Phased Reinforcement Learning)。
从短文本逐步过渡到长文本。例如,先训练模型处理2万token的文本,稳定后再增加到6万token,最后到128K。每个阶段只关注对应长度的文本。
此外还引入了难度感知的回溯采样机制。在进入下一阶段时,会保留前一阶段中最难的样本(平均准确率为零的那些),确保模型不会”忘记”如何处理困难案例。

长文本问答的答案往往比较开放,单纯的规则匹配太死板,可能漏掉正确答案。
QwenLong-L1在强化学习训练中采用混合奖励函数,结合了基于规则的验证和LLM-as-a-Judge。

规则验证也就是直接检查答案是否与标准答案完全一致(如数学题计算结果是否正确),再用另一个模型判断答案的语义是否正确(应对答案表述不同但意思一致的情况),两者结合避免单一规则过于严格或宽松

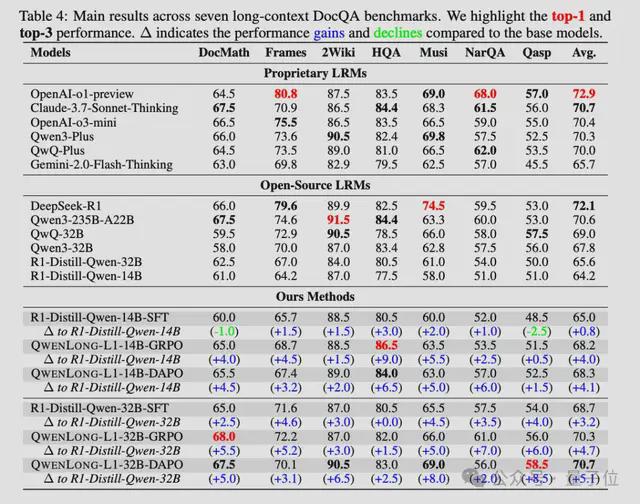
在DocMath、Frames、2WikimQA等七个长文本基准测试中,QwenLong-L1-14B相比基础模型R1-Distill-Qwen-14B,平均提升了4.1分,超越了Gemini-2.0-Flash-Thinking和Qwen3-32B。
QwenLong-L1的32B版本相比基础模型提升了5.1分,达到70.7的平均分。这个成绩不仅超过了OpenAI-o3-mini(70.4分)、Qwen3-235B-A22B(70.6分),甚至和Claude-3.7-Sonnet-Thinking(70.7分)打成平手。
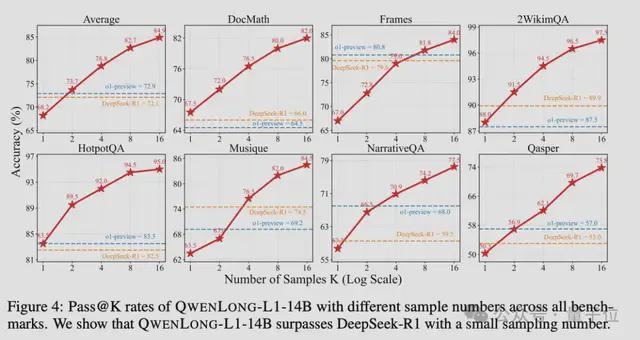
团队还针对Test-time Scaling性能做了评估。当生成16个候选答案时,QwenLong-L1-14B的表现超过了DeepSeek-R1和OpenAI-o1-preview。
最后论文中还深入探讨了两个问题:
- 既然SFT相对简单便宜,为什么还要费劲搞强化学习(RL)?
实验结果很有启发性。长文本SFT确实能带来2.6分的提升,比短文本SFT的效果更好。但是,如果在长文本SFT的基础上再做RL,提升幅度只有0.3分;而在短文本SFT基础上做RL,却能提升3.2分。
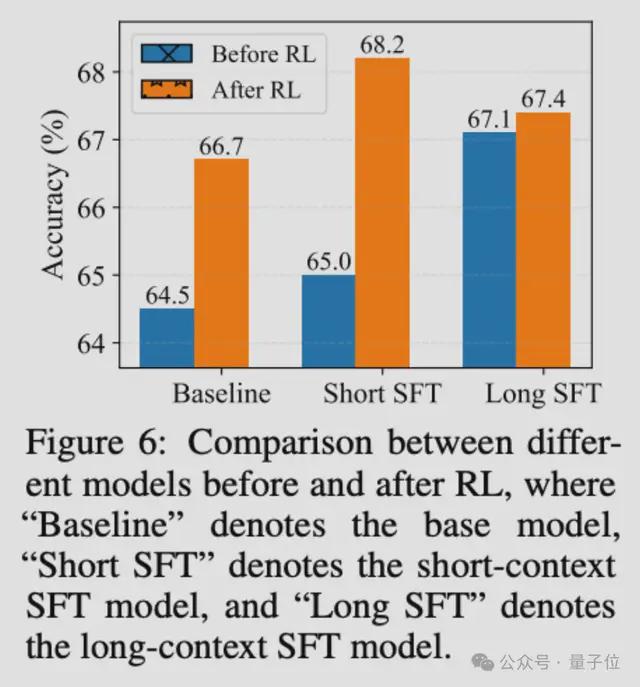
对此团队提出一个观点:SFT提供了一种经济的性能提升方式,而RL则是达到最优性能必不可少的。
通过跟踪分析了四种关键推理行为发现3个结论:信息定位(grounding)、子目标设定(subgoal setting)、回溯(backtracking)和验证(verification)。
- 所有模型都展现出明显的推理行为,尤其是信息定位行为出现频率最高,这证明了它在处理上下文依赖推理时的重要性;
- 强化学习训练过程中,这些行为会逐渐增强,并与性能提升高度相关,表明强化学习能有效调整输出空间,优先保留有助于得出准确解答的推理模式
- 虽然SFT模型也能学会这些行为,但这些表面上的行为模仿并没有带来实质性能提升,这揭示了SFT更关注表面模式匹配,而非实质推理能力的培养。
论文地址:
https://arxiv.org/pdf/2505.17667
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/16925.html