


人脑网AI前瞻(公众号:zhidxcomAI)
作者 江宇
编辑 漠影
人脑网AI前瞻5月26日消息,Plexe AI作为Y Combinator的孵化项目,近日正式公开亮相。 这家入选Y Combinator 2025年春季批次孵化项目的初创公司,正专注于开源智能体(Open-source Agent)开发,以简化机器学习(LM)模型的创建与应用流程。
在当前人工智能技术快速发展的背景下,机器学习模型的开发与部署对非专业人员而言仍存在一定技术门槛。Plexe AI正致力于解决这一痛点,据其官方资料显示,其智能体已能帮助企业将从想法到部署模型的时间缩短10倍。

一、用自然语言生成模型,Plexe AI要让AI人人可用
Plexe AI的核心愿景是创建一个开源智能体,能够将自然语言的任务描述转化为可用的机器学习模型。
这意味着,用户无需深入了解复杂的编程语言、算法原理或专业数据科学知识,即可让AI完成数据分析或预测任务。
例如,用户可以通过日常语言表达“我想分析一下客户购买行为,找出哪些因素会影响购买量”,Plexe AI便能自动构建并部署一个机器学习模型来完成该任务。
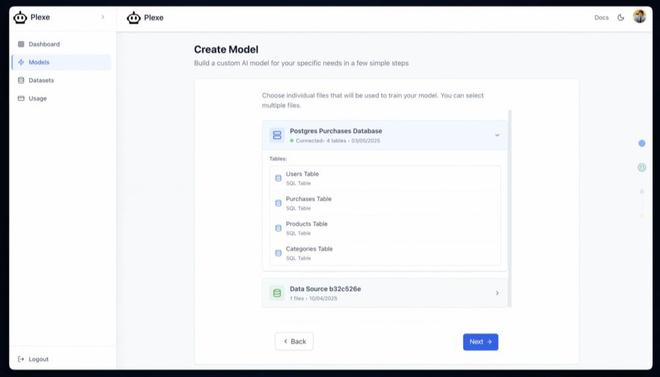
而Plexe AI的这项核心能力,正是由其两位联合创始人Vaibhav Dubey和Marcello De Bernardi所搭建。
两位创始人在机器学习领域拥有丰富经验,Vaibhav Dubey曾任职于Proofpoint和Expedia,并毕业于伦敦帝国理工学院;Marcello De Bernardi曾任职于AWS和Expedia,并毕业于牛津大学。
根据Y Combinator的介绍,他们此前在为一家大型银行构建聊天机器人时相识,并积累了企业级机器学习解决方案的经验。
二、具有自纠正能力的多智能体系统
Plexe AI的核心技术是一个多智能体系统(multi-agent system)。这并非简单的脚本自动化,而是一个“自纠正的机器学习工程智能体团队”。
它模拟了机器学习工程师的工作流程,将复杂任务拆解并自动化,具体步骤如下:
1、连接数据源并发现相关字段:
以一名营销负责人为例,他即便手头积累了大量客户数据,但也并非数据专家。
当他提出“预测哪些客户最有可能复购”的需求时,Plexe AI能够智能地连接到企业的CRM或销售数据库,并自动识别出与客户购买行为相关的关键字段,如购买频率、上次购买时间、产品偏好等。
这意味着用户无需手动进行繁琐的数据清洗和预处理,系统已完成了第一步的数据“理解”。
2、研究与实验多种模型架构:
针对该复购预测问题,Plexe AI的智能体团队会像真正的ML工程师一样,研究并实验多种潜在的机器学习模型架构。
这包括探索不同的算法(如分类算法、回归算法)、特征工程方法(如何从现有数据中生成新特征)等,以寻找最佳的预测方案。
3、评估、提炼并部署最优模型:
在实验过程中,Plexe AI会不断评估这些模型的性能,进行迭代优化和提炼,最终选择出表现最佳的模型。通过历史数据验证,确定哪个模型在预测复购率上最准确。
这个最优模型随后会通过API端点部署,让营销负责人可以直接调用和使用,将其预测能力集成到日常的客户管理或营销活动中。
这种“从描述到部署”的自动化流程,极大地降低了机器学习的门槛。它使得用户的销售数据、用户行为数据、库存数据等不再是静态信息,而是能够转化为可操作的洞察和预测,支持更明智的决策、优化运营并识别新的商机。
面对快速变化的市场,Plexe AI的自动化能力使得用户能够更快速地测试不同假设并调整策略。
作为一款开源工具,Plexe AI不仅服务于企业,也为广大开发者和个人提供了AI工具,使非专业的开发者也能通过Plexe AI的接口将AI能力集成到其应用中,实现创新。
结语:当AI打造AI,定制化AI之路能否走通?
PlexeAI的出现,为机器学习领域降低技术门槛,并加速定制化AI部署提供了新的思路。
其通过开源智能体实现自然语言到ML模型的转化,这与当前市场上的自动化机器学习(AutoML)平台(如Google Cloud AutoML、DataRobot)和低代码/无代码AI平台(如Microsoft Power Platform、Obviously.ai)在目标上有所重合。
然而,Plexe AI的差异化在于其直接通过自然语言提示驱动端到端模型构建,并采用了开源智能体这一独特的模式,有望实现更深层次的自动化和更高的开放性。
根据其Y Combinator页面信息,他们正在积极寻求与拥有大量数据但尚未构建机器学习功能的公司进行合作,以推动其技术的实际应用。
Plexe AI能否在日益增长的AI智能体和自动化工具市场中脱颖而出,推动定制化AI的广泛应用,值得行业持续关注。
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/17023.html