
这个对人类来说非常简单的问题,连GPT-4o这样级别的视觉语言大模型(VLMs)也可能答错。
究其根本,还是当前的视觉语言大模型在大规模图文数据中学习到的空间信息往往是片段化的,仅限于静态视角的理解,缺乏多维度、多视角的空间推理能力
因此,当面对需要多视角空间推理的任务时,这些模型们就频频卡壳。


但是,具备稳健的空间推理能力与视角理解能力的AI系统,才能真正成为与人类协作的智能体。
为此,来自浙江大学、电子科技大学和香港中文大学的研究团队提出了首个系统评估VLM多视角多任务下的空间定位能力的基准体系
ViewSpatial-Bench,涵盖五种不同的任务类型,从相机和人类视角出发,全面评估模型的空间推理能力。
同时还并配备了能够生成精确方向标签的自动化3D标注流水线。通过高效的3D方向标注生成流程,实现了超过5700个问答对,覆盖丰富的3D场景。
通过在多视角空间数据集上的微调,ViewSpatial-Bench团队实现了模型性能的整体提升46.24%。

五大任务,覆盖双重视角
ViewSpatial-Bench评估集中包含5700个问答对,涵盖相机视角与人类视角两种框架下的五种空间定位识别任务

如图所示,无论图像聚焦的是场景布局还是人物动作,该基准测试要求模型在不同场景中准确理解空间结构并进行定位,系统性评估多模态模型的跨视角空间推理能力,其中包括:
从相机视角出发的两类任务,主要评估视觉语言大模型基于自我视角的直观空间理解能力。
- 物体相对方向识别:直接基于图像判断物体之间的空间关系。
- 人物视线方向识别:从相机视角识别图中人物的注视方向。
还有三类任务从人类视角出发,聚焦于模型是否具备抽象的、依赖感知的空间理解能力。分别是:
- 物体相对方向识别:从图中人物的视角,判断其他物体与其的空间关系。
- 人物视线方向识别:假设自己处于图中人物的位置,推断其面朝的方向。
- 场景模拟的相对方向识别:通过模拟“自身”在场景中位置判断物体的相对位置。
为构建高质量的空间推理评估基准,研究团队基于ScanNet和MS-COCO两大经典视觉数据集,开发了完整的自动化数据构建流水线。
构建流程如下:
首先从场景中选取包含丰富三维信息的图像,结合现有标注信息精准提取物体位置坐标或人物姿态方向。
随后基于这些三维坐标或朝向角度计算各类相对空间关系,通过精心设计的自然语言模板自动生成语义明确的问答对,最终经过人工验证确保质量。
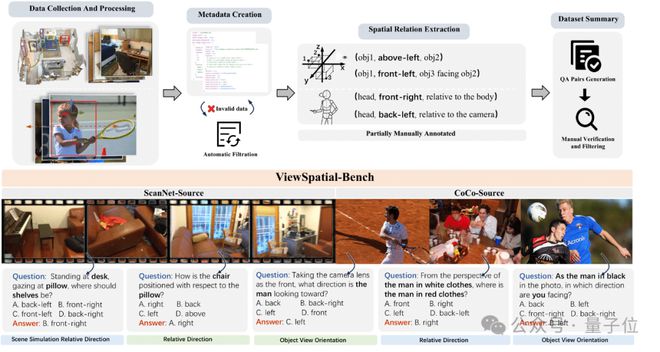
这一自动化处理方式在保证数据规模化和高效率的同时,兼顾了空间关系的准确性和语言表述的多样性,为模型训练和评估奠定了坚实的数据基础。
多模态大模型并未真正理解空间结构
基于构建的 ViewSpatial-Bench,研究团队系统评估了包括GPT-4o、Gemini 2.0、InternVL3、Qwen2.5-VL等在内的十余种主流模型的表现,结果显示:
在真正理解空间关系上,当前VLMs的表现还远远不够
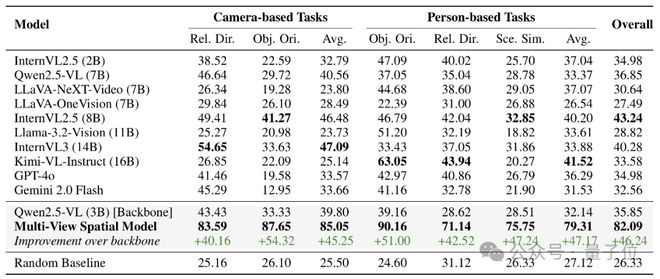
从整体准确率来看,多个顶尖模型在ViewSpatial-Bench上的得分并不高。
这表明,尽管模型具备基本的图像理解能力,但在涉及多视角空间定位时,仍缺乏空间感与换位思考能力
更值得关注的是不同任务类型间的显着表现差异。
在摄像头视角下,模型在人物面朝方向判断任务上的平均准确率仅为25.6%,远低于”物体相对方向判断”的38.9%。然而在人物视角下,这一趋势却完全反转。
这种“任务-视角”交叉表现的失衡揭示了当前VLMs的核心缺陷:它们无法构建统一的三维空间认知框架来支持跨视角推理
实质上,模型并未真正理解空间结构,而是将不同视角下的推理过程割裂处理,缺乏从统一空间表征中灵活调度信息的能力。
有趣的是,实验结果还揭示出一个反直觉的现象:
大多数模型在人物视角的任务上表现略优于摄像头视角
例如,GPT-4o 在人物视角平均准确率为36.29%,略高于摄像头视角的33.57%;InternVL2.5、Kimi-VL也表现出类似趋势。
这一现象打破了我们对“自我视角更易处理”的常识性认知,这与上面任务表现的失衡有直接联系,说明模型在训练过程中可能存在学习了更偏“第三人称”视角的空间分布规律,而缺乏从相机视角进行空间映射的能力。
这种偏差揭示了当前训练语料在视角分布上存在结构性不平衡,为未来的数据构建和模型优化指明了重要方向。
如何让模型理解“换位思考”
针对当前视觉语言大模型在多视角空间推理方面的根本性局限,研究团队开发了Multi-View Spatial Model(MVSM)专门用于跨视角空间理解进行系统性优化
MVSM采用自动化空间标注框架生成了约43000个高质量的多样化空间关系样本,全面覆盖ViewSpatial-Bench的五个任务类别。
实验结果显示,在ViewSpatial-Bench上,MVSM相比其骨干模型Qwen2.5-VL实现了46.24%的绝对性能提升,充分验证了针对性训练在解决空间认知缺陷方面的有效性。

如上图所示,为了进一步验证MVSM的空间理解能力,研究团队在VSI-Bench和自建的ViewSpatial Interaction Application Dataset(VSI-App)上进行了评估。
在VSI-Bench中,MVSM在需要视角转换能力的物体相对方向任务上取得了0.93%的提升,在路径规划任务上更是实现了9.54%的显着改进。

VSI-App包含50个场景(25个室内,25个户外),专门设计用于评估具身交互环境中的人类中心空间推理。
在这个更贴近现实的测试中,MVSM依然取得了显着领先,尤其在结构更清晰的室内场景中表现尤为出色(提升+20%),在户外场景中也有适度提升(+4.00%)
以上结果证明,MVSM不仅能够建模静态空间关系,还能处理穿越3D环境的动态轨迹以及人机交互场景——这些能力都是从视角感知训练方法中自然涌现的,而非通过显式的优化获得。
ViewSpatial-Bench和MVSM的提出不仅为多模态模型的空间理解能力提供了系统评估工具,也首次在数据和训练范式上重构了“视角采择”这一关键人类认知能力的建模方式。
通过建立首个多视角空间推理基准并实现显着的性能突破,为AI系统获得类人空间认知能力提供了可行路径:
更聪明的空间感知,是下一代机器人与多模态助手的关键一步。
论文链接:
https://arxiv.org/abs/2505.21500
项目主页:
https://zju-real.github.io/ViewSpatial-Page
GitHub仓库:
https://github.com/ZJU-REAL/ViewSpatial-Bench
— 完 —
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/18364.html