
监督学习也能像强化学习一样进行“自我反思”了。
清华大学与英伟达、斯坦福联合提出新的监督学习方案——NFT(Negative-aware FineTuning),在RFT(Rejection FineTuning)算法基础上通过构造一个“隐式负向模型” 来额外利用负向数据进行训练。
这并不意味着使用“差数据”进行训练,而是在已知的模型计算结果前提下,通过负向数据训练正向模型,即“隐式负向策略(Implicit Negative Policy)”
这一策略弥合了监督学习和强化学习的差距,使得两者性能基本持平。
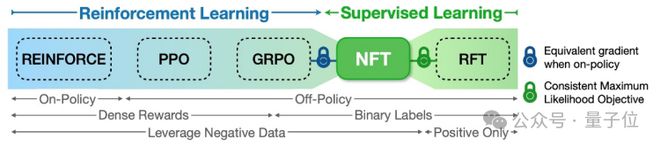

△架构图语言模型在线强化算法光谱图
更让人惊讶的是,NFT损失函数梯度和GRPO在On-Policy条件下是等价的!这意味着,GRPO中人为经验设置的“Group Relative Normalization”方案,可以直接通过理论推导自然得出。
方法:负向策略计算出正向模型
NFT定义了一个在线强化过程:
1.数据采样:语言模型自己产生大量数学问题答案,通过一个01奖励函数,把答案分为正确和错误两类,并统计每个问题回答准确率[数学公式]。
2.隐式策略建模:利用原始模型和待训练正向模型,构造一个隐式负向策略来建模负向数据。
3.策略优化:在正确数据上,直接监督训练正向策略模型;在错误数据上,通过用隐式负向策略拟合建模,达到直接优化正向策略模型的目的。
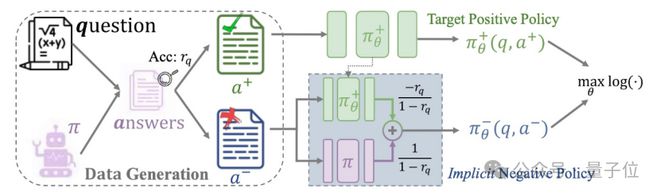
考虑这样一个监督学习基线:Rejection sampling Finetuning(RFT)。每一轮,研究团队让模型自己产生大量数学问题答案,通过一个01奖励函数,把所有模型产生的错误答案丢弃,仅在高质量正向数据上进行监督训练。
RFT中,研究团队每一轮的训练目标是:
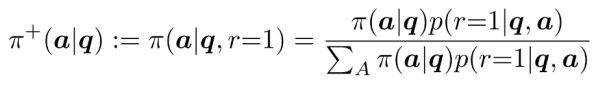
问题关键在于:能否在负向数据上监督训练,也同样得到上面的“正向策略”呢?
乍看上去是不可能的,在负向数据上训练只能得到没有用的“负向策略”。
然而,问题的转折点在于,数据是已知模型在线采样的,也就是正负向数据分布的和是已知的。由贝叶斯公式可知以下线性关系:

这说明,假设真能在负向数据上学习到一个“负向策略”,可以把这个负向策略和原始生成策略结合,“计算”得出想要的正向模型。
在实际操作中,不是真的去学习一个“差模型”。研究团队提出“隐式负向策略”(Implicit Negative Policy),可以直接在负向数据上训练正向策略。可用以下表达式来参数化隐式负向模型:
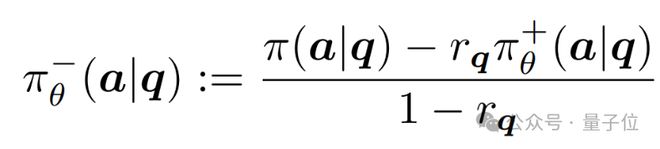
其中rq表示模型在回答问题q时的正确率,现实中由于模型对一个问题会产生多个回答,我们可以很容易地估计rq。这里表明隐式负向策略不是一个静态的模型,而是基于不同难度的问题动态构造的
因此,NFT损失函数就可以表达为:
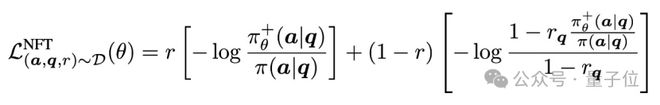
对以上损失函数直接求导,研究团队在严格On-policy条件下得到和GRPO等价的梯度表达式。
这暗示了监督学习和强化学习或许存在深层的联系,也直接说明NFT是一个绝对可靠的算法,最差也是退回On-Policy训练和GRPO等价。
结果:监督强化学习方案性能持平,负向反馈在大模型中优势更加明显
NFT和当下性能最优的强化学习算法性能持平,部分场景下可能更有优势(可以在现有监督学习框架基础上简单实现)。
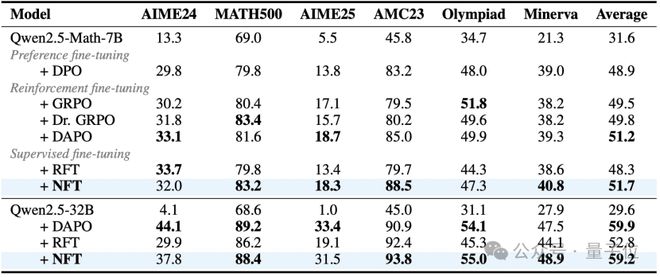
与主流RLHF算法对比,NFT7B性能超过GRPO、DAPO;32B性能和DAPO基本持平。研究团队还观察到,模型越大,NFT和RFT算法性能差异越明显。这暗示了负向反馈在大模型中承担更重要的作用。
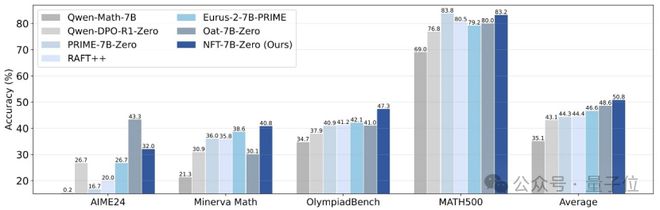
和其他已有的基于Qwen-7B zero style训练模型相比,NFT达到最高的数学平均成绩。
作为一个纯监督学习算法,NFT不依赖任何外界数据,可实现数学能力的大幅提升。
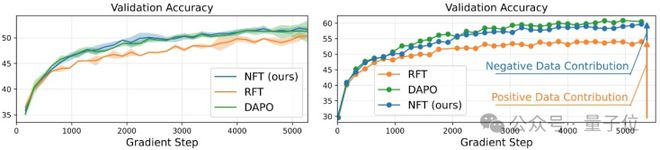
△架构图NFT在Qwen-7B(左)和32B模型(右)上性能表现及对比
研究团队还发现NFT算法在不损失性能条件下有利于模型熵增加,鼓励模型充分探索。
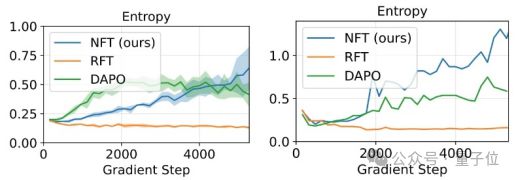
NFT算法指出并弥合了强化学习和监督学习的本质差异,这暗示两套机器学习理论存在深层联系,可以帮助研究者重新定位、思考和放大强化训练的本质优势。
项目网页: https://research.nvidia.com/labs/dir/Negative-aware-Fine-Tuning/
论文链接: https://arxiv.org/pdf/2505.18116
项目代码: https://github.com/NVlabs/NFT
— 完 —
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/21482.html