

人脑网
作者 程茜
编辑 心缘
阿里通义大模型新成员Qwen3系列终于亮相!
人脑网4月29日报道,今日凌晨4点,阿里云正式开源Qwen3系列模型,包含2个MoE模型、6个稠密模型。发布2小时,Qwen3模型在GitHub上的star数已超过16.9k。
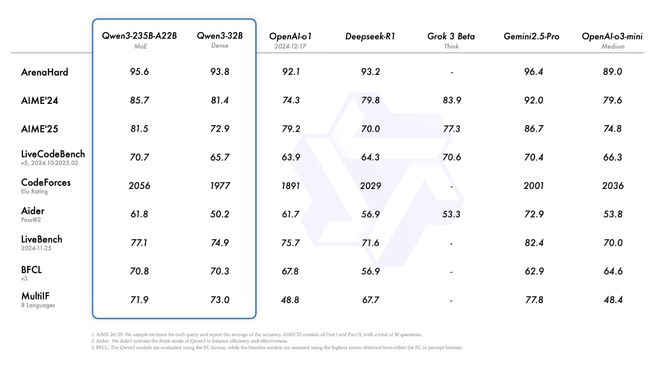
其中旗舰模型Qwen3-235B-A22B,在编程、数学、通用能力等基准评估中的表现优于DeepSeek-R1、OpenAI o1、OpenAI o3-mini、Grok-3和Gemini-2.5-Pro等业界知名模型。

此次全新升级的Qwen3系列有以下5大关键特性:
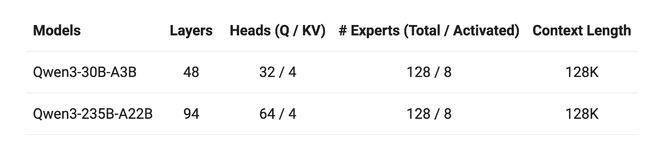
8种参数大小的稠密与MoE模型:0.6B、1.7B、4B、8B、14B、32B和Qwen3-235B-A22B(2350亿总参数和220亿激活参数)、Qwen3-30B-A3B(300亿总参数和30亿激活参数);
引入混合思考模式:用户可切换“思考模式、“非思考模式”,自己控制思考程度;
推理能力提升:在数学、代码生成和常识逻辑推理方面超越QwQ(在思考模式下)和Qwen2.5 instruct models(在非思考模式下);
支持MCP(模型上下文协议),Agent能力提升:可以在思考和非思考模式下实现大语言模型与外部数据源和工具的集成,并完成复杂任务;
支持119种语言和方言:具备多语言理解、推理、指令跟随和生成能力。

目前,Qwen3系列模型已在Hugging Face、ModelScope和Kaggle等平台上开源,均遵循Apache 2.0许可证。在部署方面,其博客提到,建议开发者使用SGLang和vLLM等框架,并推荐本地部署的开发者使用Ollama、LMStudio、MLX、llama.cpp等工具。
值得一提的是,Qwen3模型采用了不同的命名方案,后训练模型不再使用“-Instruct”后缀,基础模型的后缀是“-Base”。
体验地址:https://chat.qwen.ai/
博客地址:https://qwenlm.github.io/blog/qwen3/
GitHub地址:https://github.com/QwenLM/Qwen3
Hugging Face地址:https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
一、以小搏大!激活参数仅1/10,实现性能反超
6个稠密模型中,0.6B~4B参数规模的模型上下文长度为32K,8B~32B参数规模的模型上下文长度为128K。

2个MoE模型的上下文长度均为128K。
小型MoE模型Qwen3-30B-A3B,在激活参数是QwQ-32B的1/10的情况下,实现了性能反超。且参数规模更小的Qwen3-4B模型,实现了与Qwen2.5-72B-Instruct的性能相当。
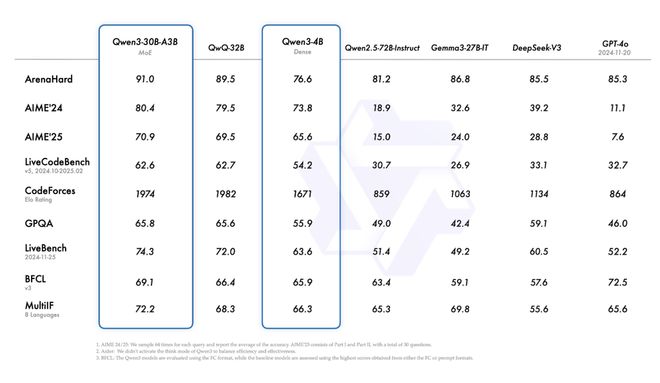
其他基准测试评估结果显示,Qwen3-1.7B/4B/8B/14B/32B-Base的性能分别与Qwen2.5-3B/7B/14B/32B/72B-Base相当。
其博客还特别提到,在STEM、编程和推理等领域,Qwen3稠密模型的性能甚至优于参数规模更大的Qwen2.5系列模型。
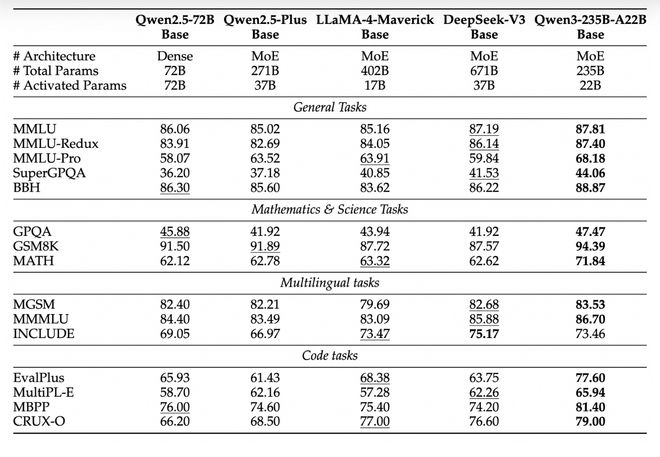
▲Qwen3系列与Qwen2.5系列基准测试对比
二、引入混合思考模式,支持119种语言、MCP协议
Qwen3系列模型的关键特性包括引入混合思维模式、支持119种语言和方言、集成MCP协议以提升Agent能力。
其中,混合思维模式指的是支持思考和非思考两种模式。
思考模式下,模型会逐步推理,花费时间给出最终答案,这适用于需要深入思考的复杂问题;非思考模式下,模型提供快速、几乎瞬间的响应,适用于对响应速度敏感的问题。
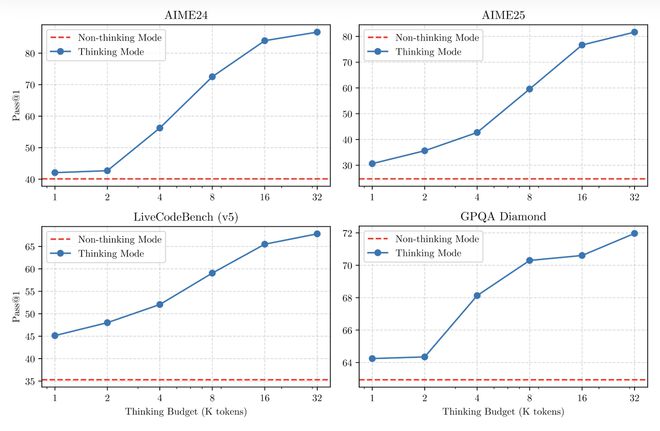
▲思考和非思考模式对比
这使得用户可以根据任务需求控制模型进行的“思考”程度。例如,对于更难的问题可以使用扩展推理来解决,而对于较简单的问题则可以直接回答,无需延迟。
此外,这两种模式的集成还增强了模型实施稳定和高效思考预算控制的能力,这种设计使用户能够配置特定任务的预算,平衡实现成本效率和推理质量。
在多语言方面,Qwen3模型支持119种语言和方言。

此外,Qwen3系列模型在编程和Agent能力方面性能提升,集成了MCP协议。
三、预训练数据集翻番,模型兼顾逐步推理、快速响应
与Qwen2.5相比,Qwen3的预训练数据集大小翻了两倍。
Qwen2.5在1800亿个token上进行预训练,Qwen3基于大约3600亿个token进行预训练。
为了这一大型数据集,研发人员收集了网络数据、PDF文档数据等,然后使用Qwen2.5-VL从这些文档中提取文本,并使用Qwen2.5提高提取内容的质量。同时,为了增加数学和代码数据量,研发人员使用了Qwen2.5-Math和Qwen2.5-Coder来生成教科书、问答对和代码片段等合成数据。
预训练过程分为三个阶段:
在第一阶段,模型在超过3000亿个token上进行了预训练,上下文长度为4K个token。这一阶段为模型提供了基本语言技能和一般知识;在第二阶段,其通过增加STEM、编程和推理任务等知识密集型数据的比例来改进数据集,并让模型在额外的500亿个token上进行预训练;第三阶段,研发人员使用高质量的长上下文数据将上下文长度扩展到32K个token,使得模型可以处理较长的输入。
在后训练阶段,为了开发既能逐步推理又能快速响应的混合模型,研发人员采取了四阶段训练流程:思维链(CoT)冷启动、基于推理的强化学习、思维模式融合、通用强化学习。
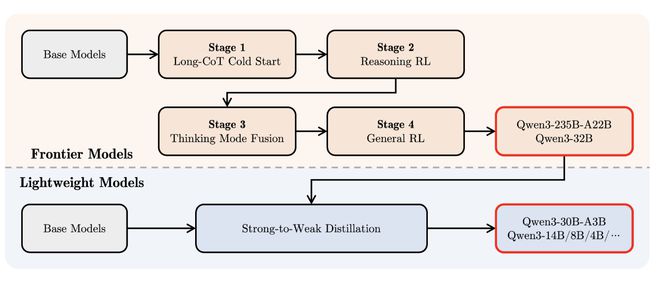
第一阶段,其使用多样化的长思维链数据微调模型,涵盖各种任务和领域,如数学、编程、逻辑推理和STEM问题,这个过程旨在使模型具备基本的推理能力。
第二阶段专注于扩大强化学习的计算资源,利用基于规则的奖励来增强模型的探索和利用能力。
第三阶段,通过在长思维链数据和常用指令微调数据组合上微调,将非思考能力整合到思考模型中。这些数据由第二阶段增强的思考模型生成,确保推理能力和快速响应能力的无缝融合。
第四阶段,其将强化学习应用于超过20个通用领域任务,包括指令遵循、格式遵循和Agent能力等任务,以进一步增强模型的一般能力和纠正不良行为。
结语:Agent生态爆发前夜,优化模型架构和训练方法推进智能升级
通过扩大预训练和强化学习的规模,可以看到Qwen3系列模型以更小的参数规模实现了更高的智能水平,其集成的混合思考模式,使得开发者能更灵活控制模型预算。
研发人员还提到,未来其将围绕以下几个维度继续提升模型能力:优化模型架构和训练方法,以实现扩展数据规模、增加模型大小、延长上下文长度、拓宽模态的目标,并通过环境反馈推进长期推理的强化学习。
如今,AI产业正从关注模型训练的时代过渡到一个以训练Agent为中心的时代,未来大模型能力的实际应用价值将逐渐被放大,通义大模型系列也正以此为目标继续推进升级。
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/9598.html