
开源大模型新王者,正在受到空前关注。
Qwen3预告一出,直接开启不眠夜模式。

△来自编辑部本部
等到深夜正式上线并宣布登顶全球最强开源模型,更是瞬间引爆全网热议。
网友们的反应在meme中尽数体现(doge)。

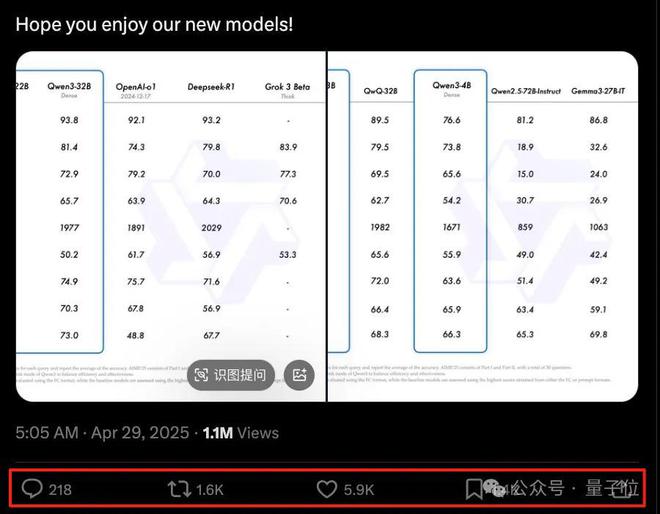
毕竟,单看纸面参数,Qwen3就是个妥妥的大工程:
- 8款混合推理模型全部开源,参数量从0.6B235B全面覆盖;
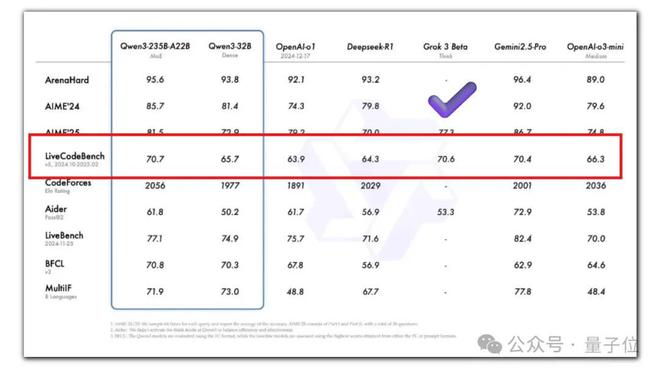
- 32B模型就有超越OpenAI o1、DeepSeek R1的性能表现,在编程基准测评中还超过了风头正盛的Gemini 2.5 Pro;
- 支持思考和非思考模式,支持119种语言和方言、加强对MCP支持……
还有网友认为,这是“又一个DeepSeek时刻”。

这一次模型开源,通义App和网页版也赶在第一时间满血上线Qwen3,并且有专属智能体体验。

新王究竟表现如何,我们第一时间深度实测,以见真章。

Qwen3住进App,还能这样玩儿
打开通义App/通义网页版首页,目前有两种方式可以体验到Qwen3模型:
- 直接用输入框对话(代码/数学/翻译类问题默认调用Qwen3-235B,其它问题不调用Qwen3)
- 选用“千问大模型”智能体(默认使用旗舰版Qwen3-235B-A22B)
BTW,通义网页版近期上线了新域名tongyi.com,不要走错。
OK,接下来进入正题。
官方强调了新模型在Agent、编码方面的能力提升,还增强了对MCP的支持。具体表现如何,我们直接在通义App里全方位实测。
第一关:代码生成
先来个新模型“入门挑战”——空间内弹小球。
这个经典测试在考验模型代码能力的同时,还重点关注了它对物理世界的理解,几乎每一个新模型都会被拉出来遛一遛。
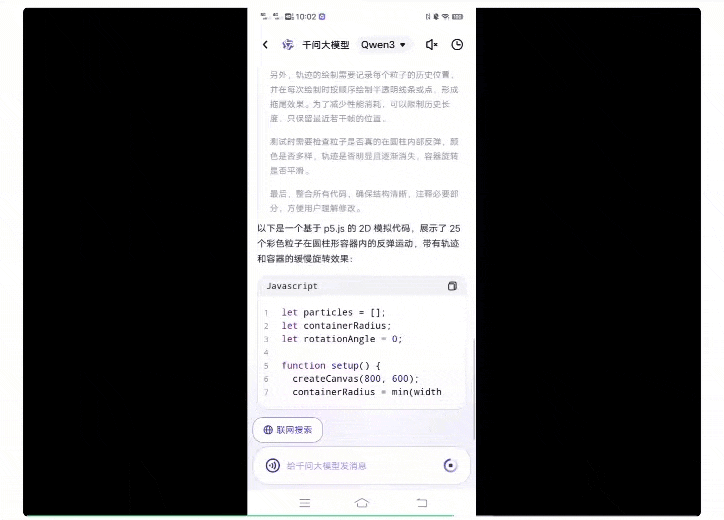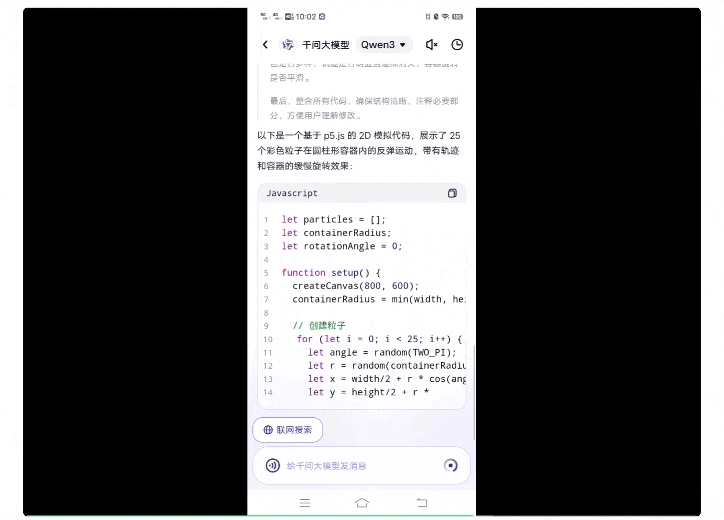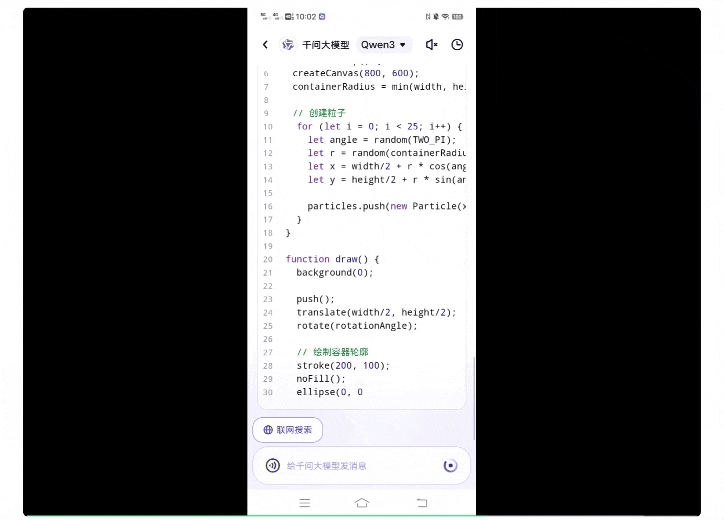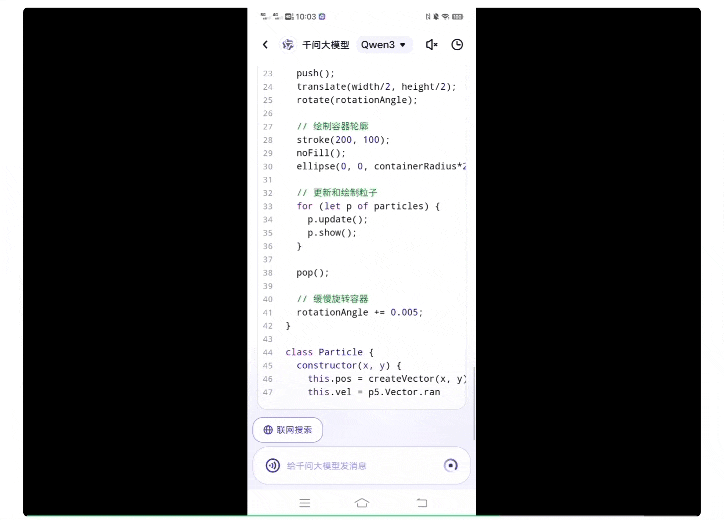
提示词如下(p5.js脚本、25个粒子、圆柱形容器):

而第一次接受挑战的旗舰版Qwen3模型,用时1分钟,唰唰唰就生成了一百多行代码:
将上述代码实际运行一下,结果be like:
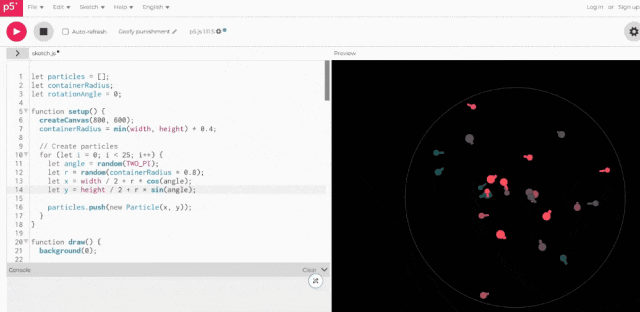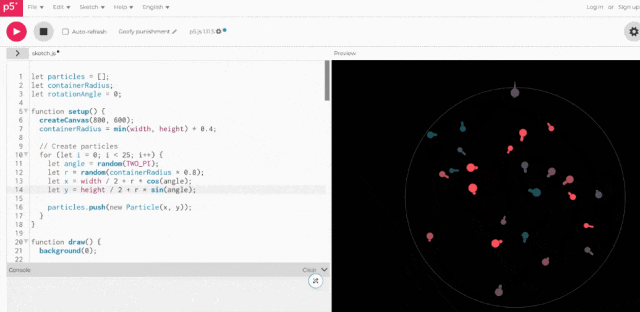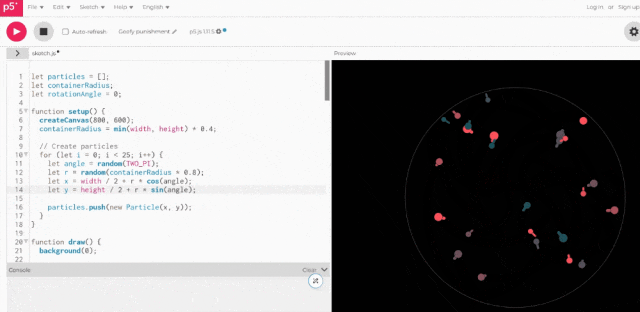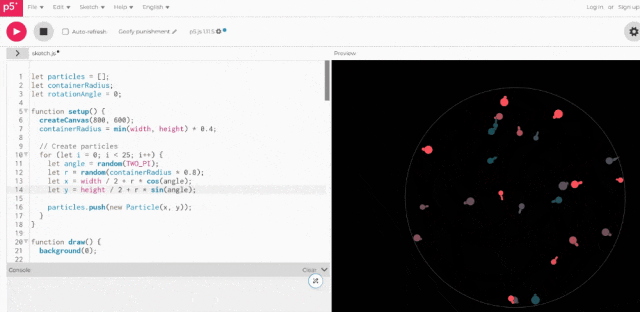
虽然一眼看去没有“小球直接冲出圆圈”这样明显的错误,但也确实缺少3D空间感。
作为对比,我们拉出官方测评图中,和满血Qwen3代码实力最相近的Grok 3模型。
重复相同操作,让Grok 3基于同一提示词生成代码,并实际运行:
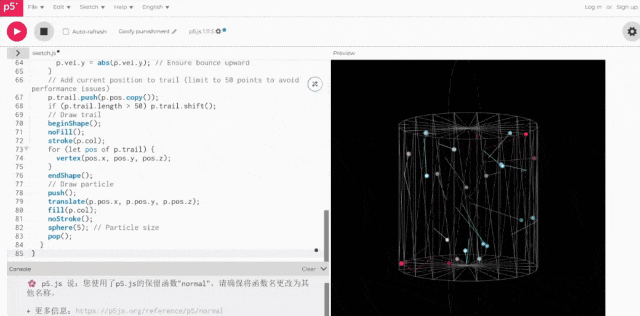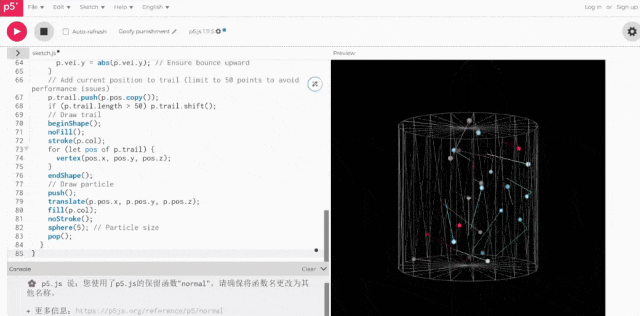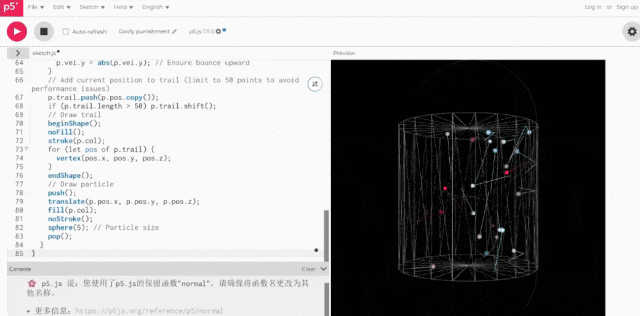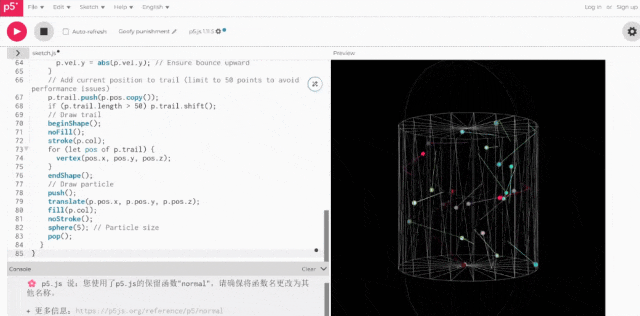
二者的区别相当明显,后者(Grok 3)的空间感肉眼可见更强。
为了进一步探究两段代码的差别,我们又直接让Qwen3“自己找找差距”(doge)。
结果,它真的很认真地进行了全方位对比,包括渲染模式、容器结构、粒子运动与碰撞测试等等。
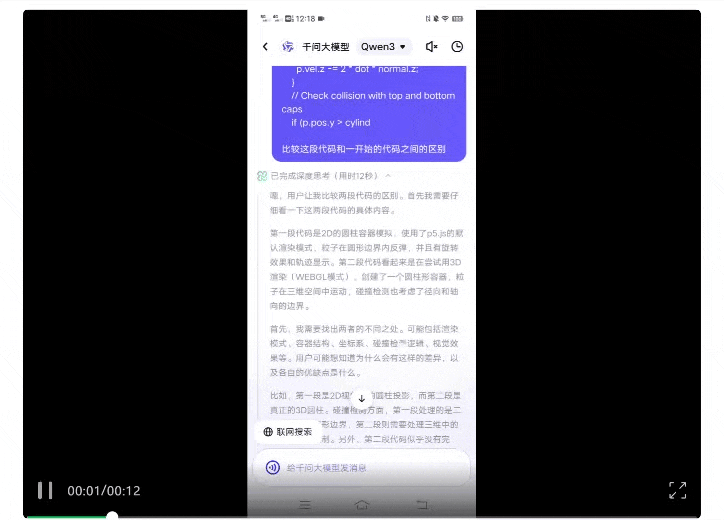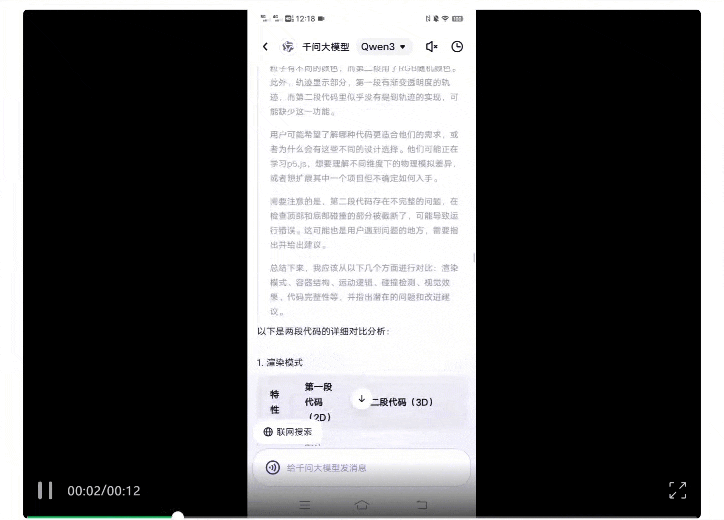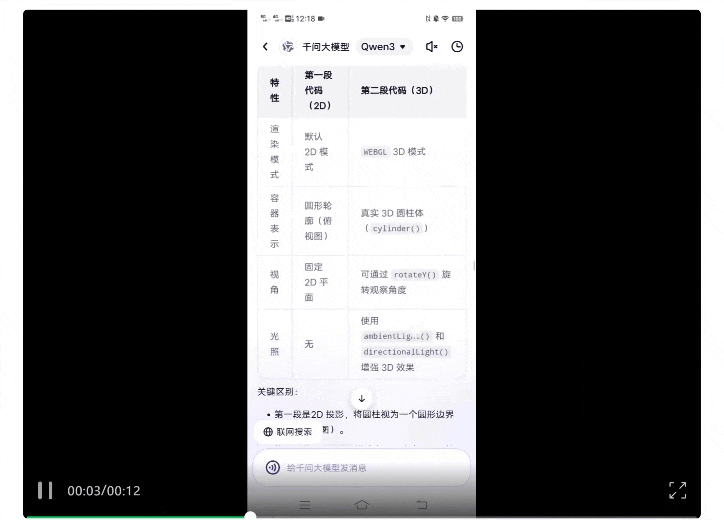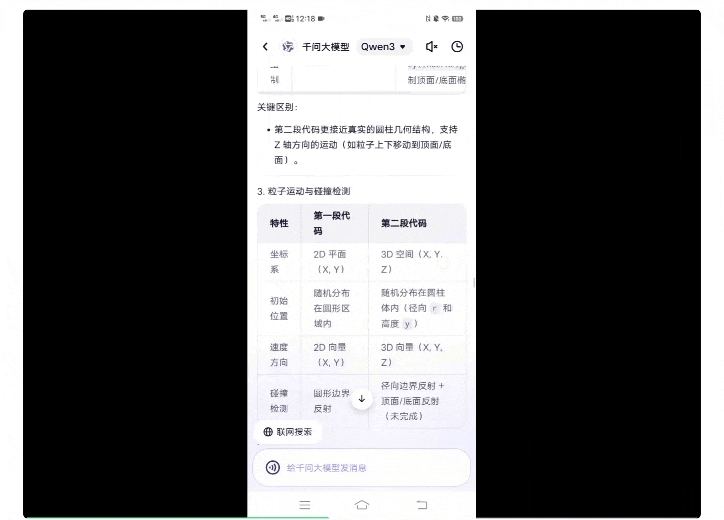
最终结论也用表格进行了呈现,一目了然:

甚至,基于它提出的改进意见,我们继续让它出了一个新版本。

实际运行后,这次的结果已经非常符合我们的要求了。
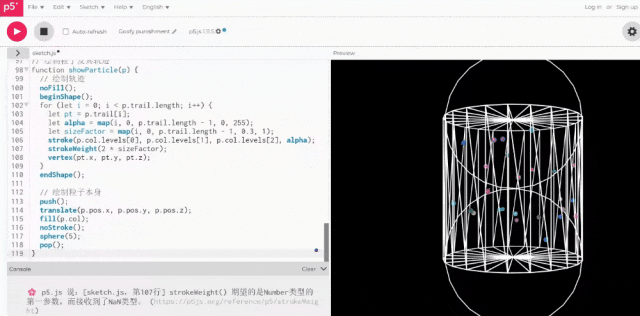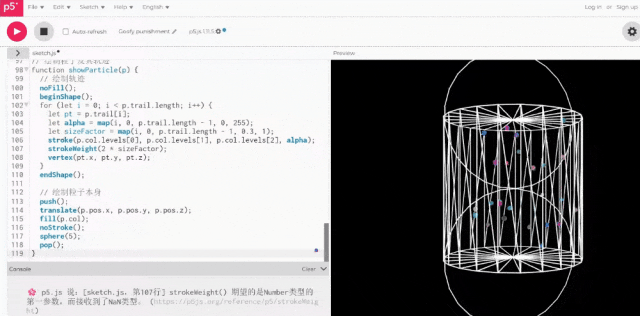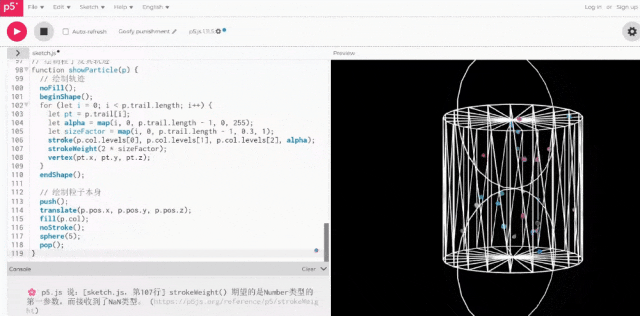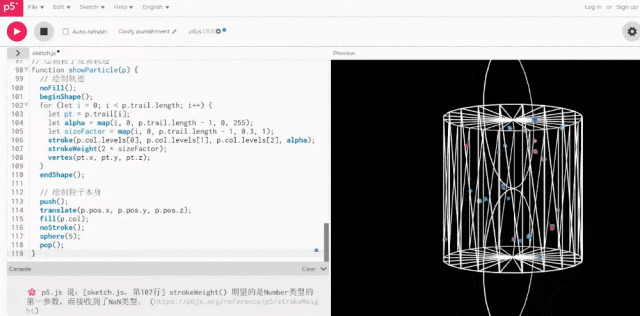
事实上,深扒Qwen3的思考过程,我们才发现原来第一版的2D效果是它“深思熟虑”后的选择。
这里主要考虑到了兼容性问题,所以简化成了俯视图来呈现。

从上面这个简单测试,我们已经能够窥见Qwen3的程序员素养确实不错。
接下来难度升级,直接让它帮打工人设计一个提醒喝水的电脑端App。
注意,为了能快速在浏览器端预览生成效果,这里我们采用了“极简模式”,仅保留最基础的功能,不涉及使用任何第三方库。
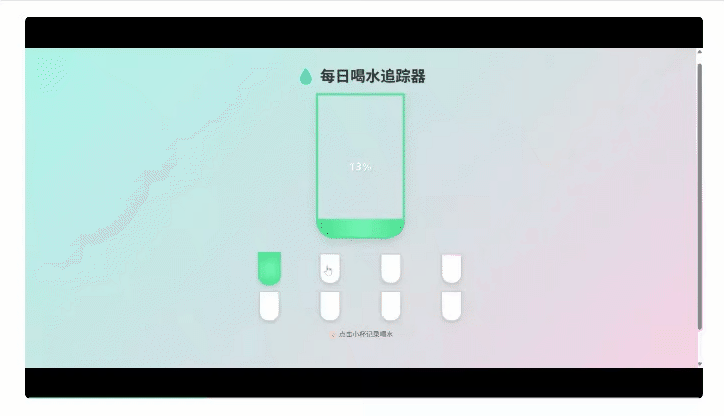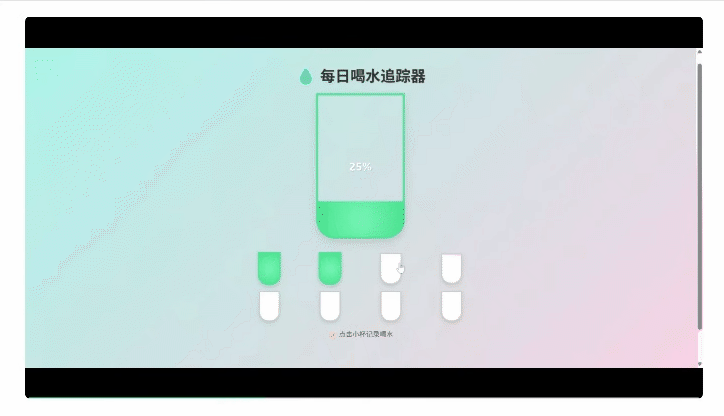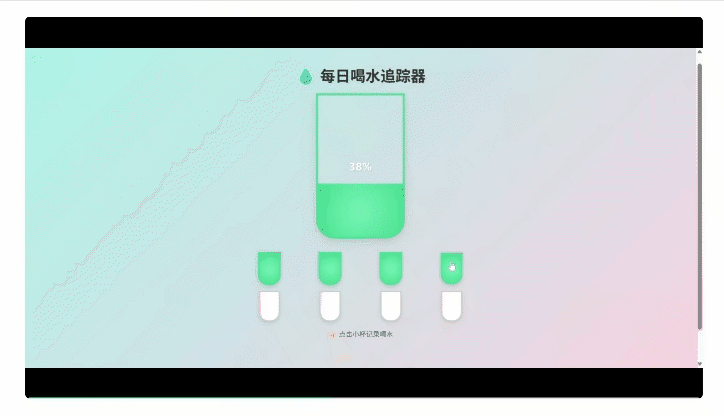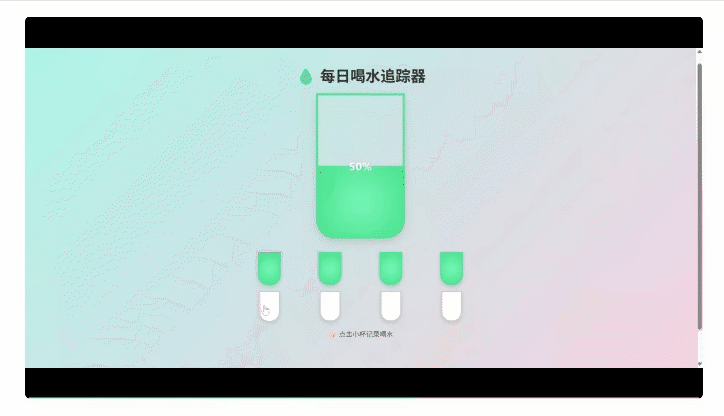
结果生成的App有模有样,还能真实点击交互。
一旦让具备工程能力的童鞋们上手,估计能实现更多复杂效果。
第二关:逻辑推理
接下来我们考查一下Qwen3的逻辑推理能力。
老规矩,先上一道经典逻辑陷阱题:
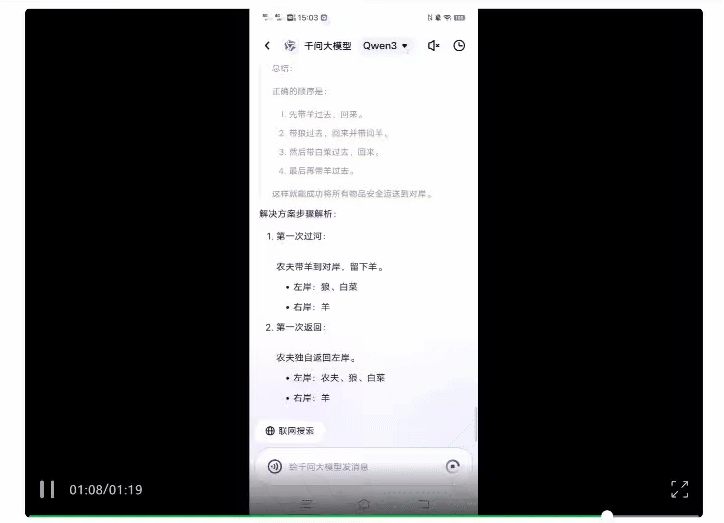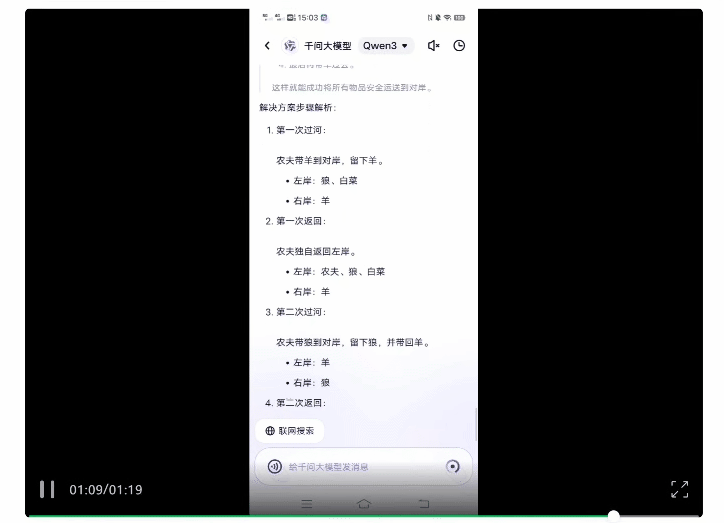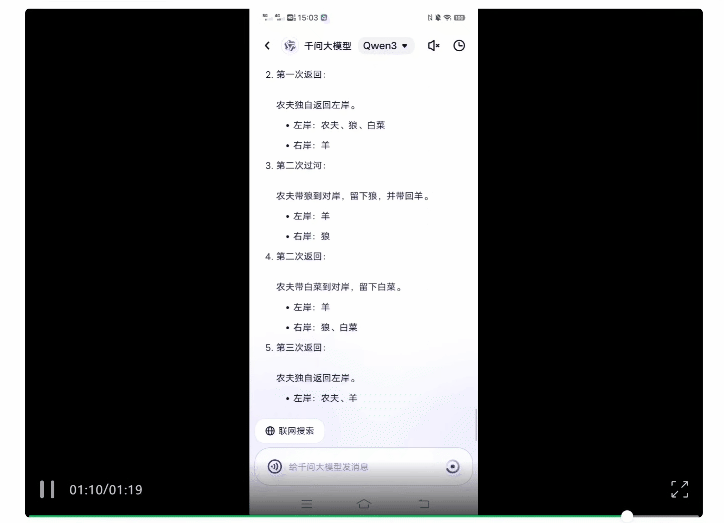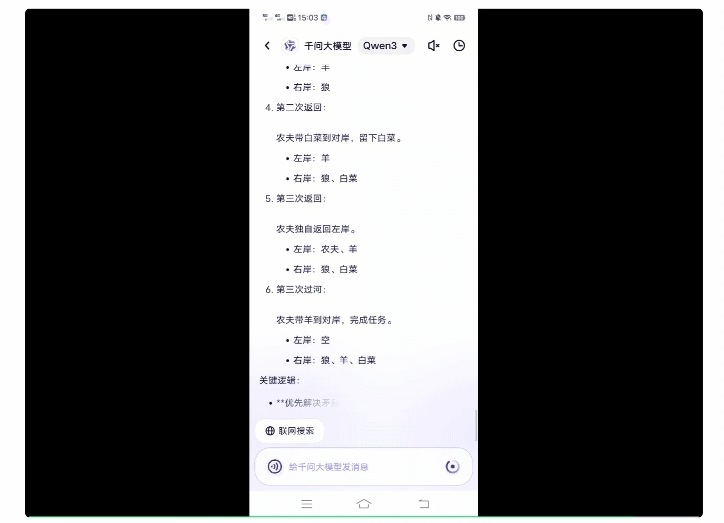
在故意关闭联网模式后,Qwen3经过一步步推理最终给出了正确答案。
而且从Qwen3的思考过程能够看到,其思维方式和人类一样,是通过不断推翻各种方案来找出可行路径。

再来一道超高难度专业数学题。
原题来自今年的普特南数学竞赛,该竞赛号称最难本科数学考试,人类要考6小时,并且所选取的题目据称前500名选手均未能完整作答。
而扔给Qwen3后,可以看到整体的思考时间确实明显变长,最终用时5分38秒给出了正确答案。
p.s. 千问智能体无法直接上传图片,最终选择从App首页上传图片,提取文字后继续使用千问智能体作答。
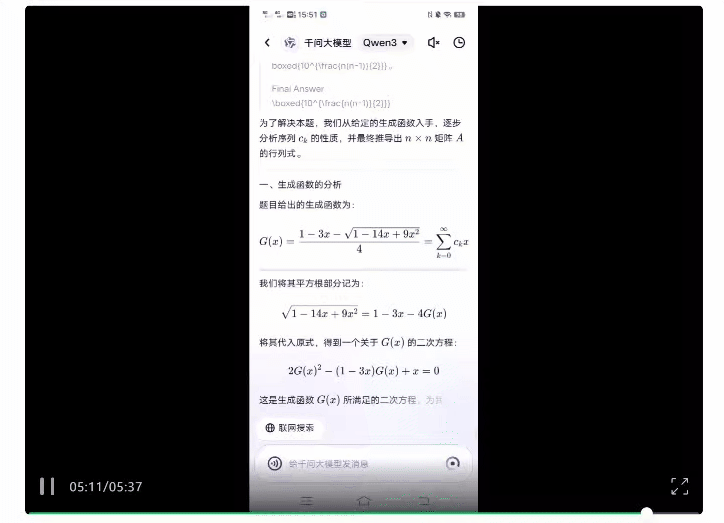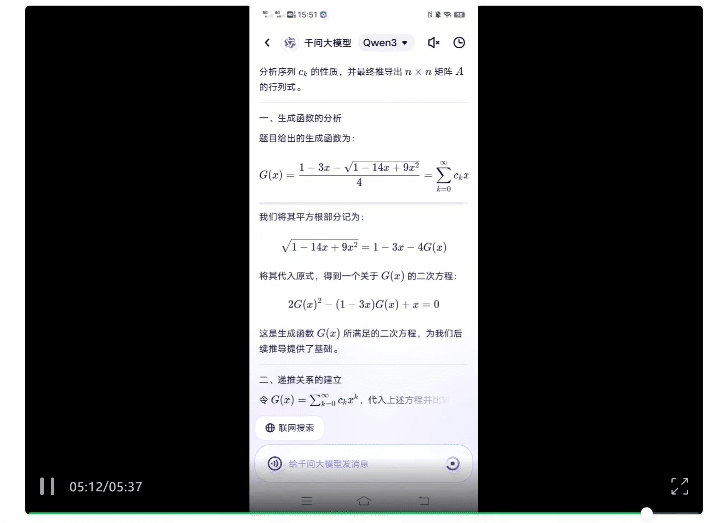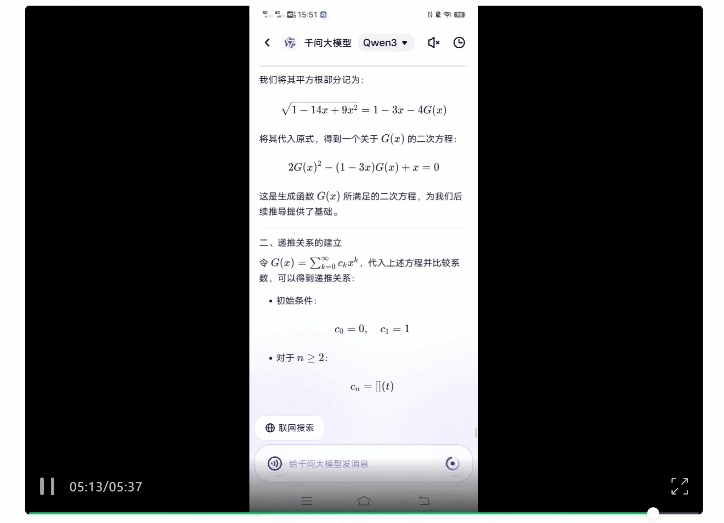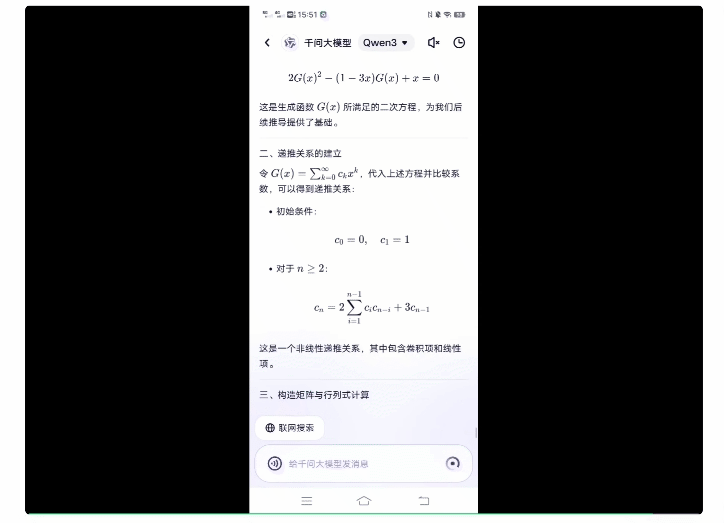
更有趣的是,扒一扒其思考过程,还能看到模型在线表演“崩溃”:

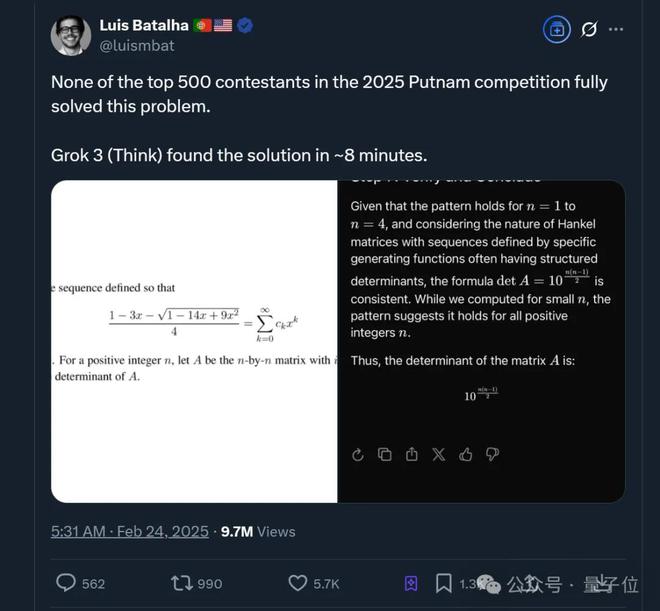
当然,虽然AI的解读速度和正确率明显胜于人类,但还是要和同类来比。
在国外网友的测试中,同一道题Grok 3(Think)在约8分钟内找到了解决方案。
所以对比下来,这一局算Qwen3略胜一筹。
第三关:多语言能力
另外据介绍,Qwen3的一大亮点是支持119种语言和方言,被网友戏称“AI届多邻国”(doge)。
别的不说,直接让它来挑战一把国内专业译者的地位试试。
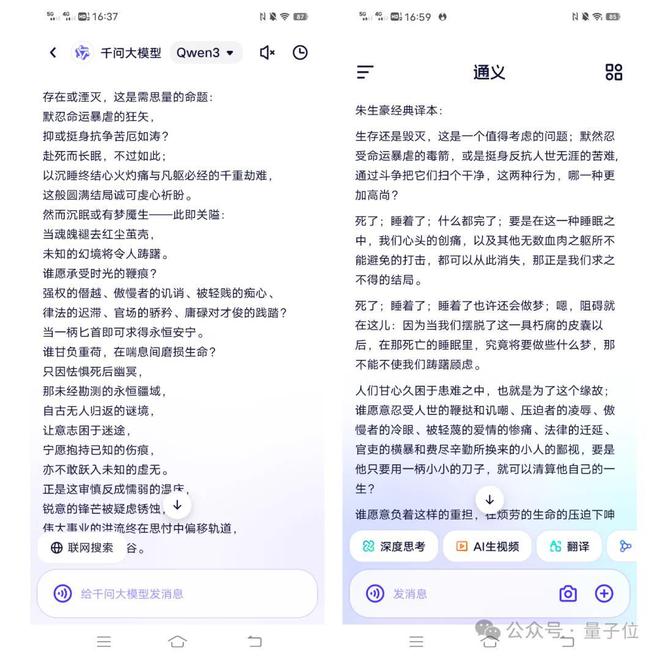
将莎士比亚《哈姆雷特》的经典选段丢给它,让它按照“信达雅”翻译成中文。
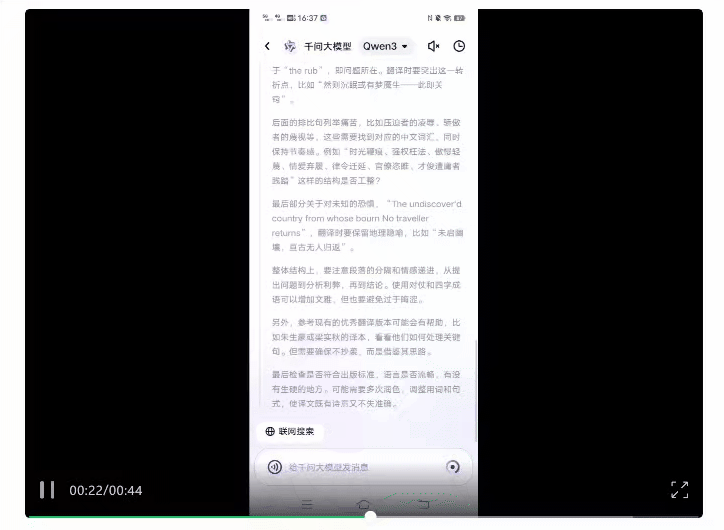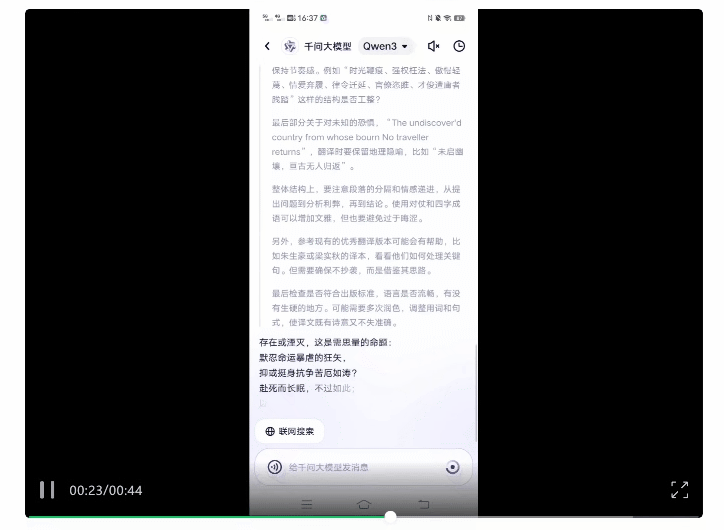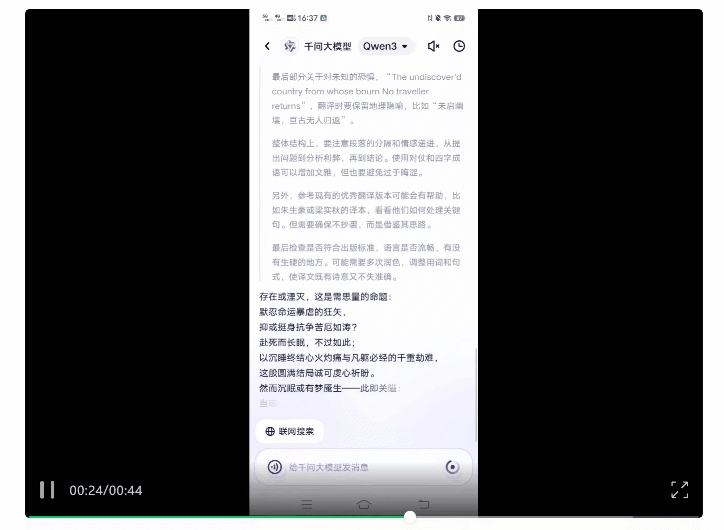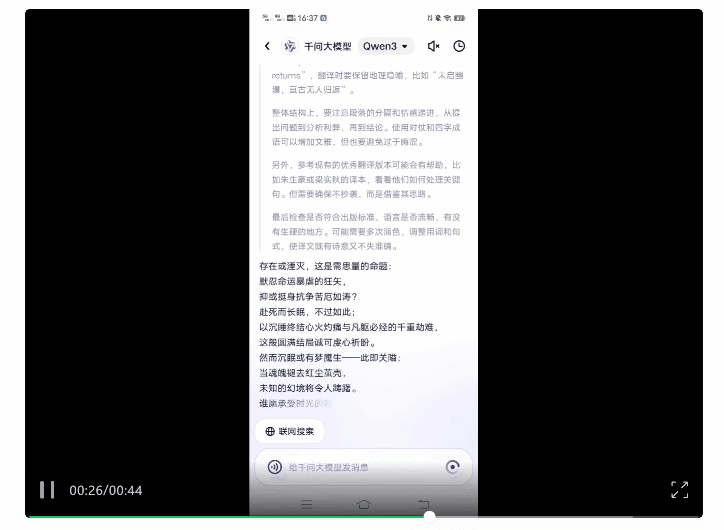
它还知道参考优秀译本,并且注意避免直接抄袭造成侵权。

最终生成的结果如下(左侧),对比我们熟知的朱生豪经典译本(右侧),你觉得AI味儿浓度如何?
第四关:赛博闺蜜、shopping比价、写歌一网打尽
除了以上更侧重模型基础能力的考查,当Qwen3被塞进App后,我们还解锁了更多玩法。
做旅游规划这种就不必多说了,关键还能充当“赛博闺蜜”,帮忙选择更适合发朋友圈的游客照。

日常也能用来购物比价,比如分析出当下最值得入手的3000元预算内平板。
不仅用表格清晰列出了各品牌的核心参数,还按照不同需求进行了推荐,一整个造福伸手党。
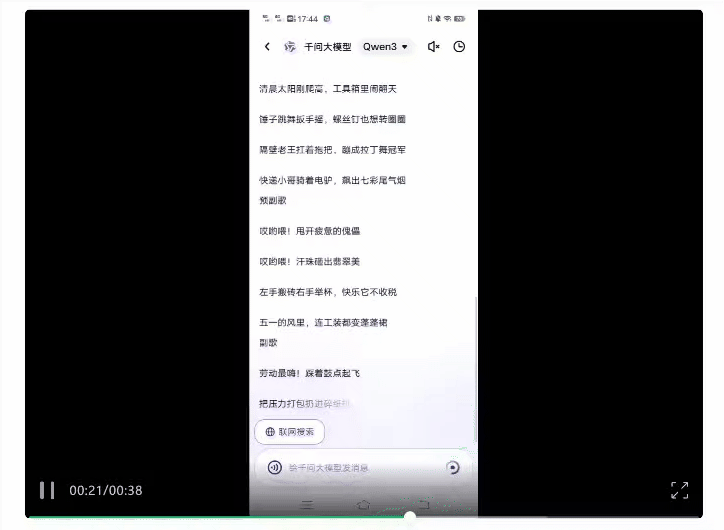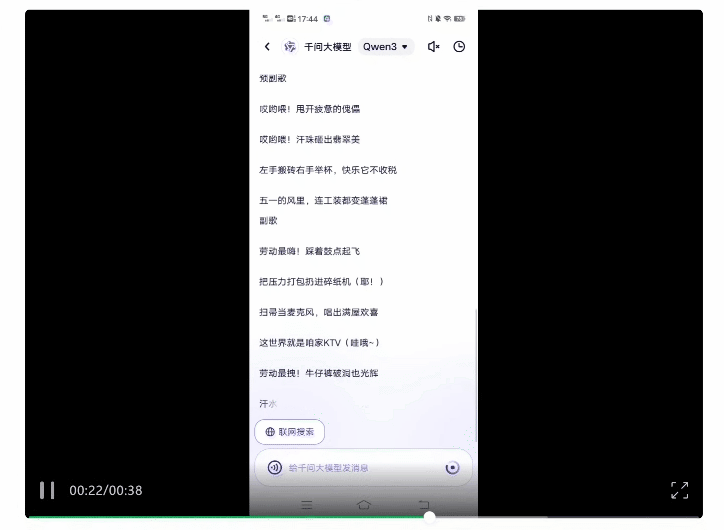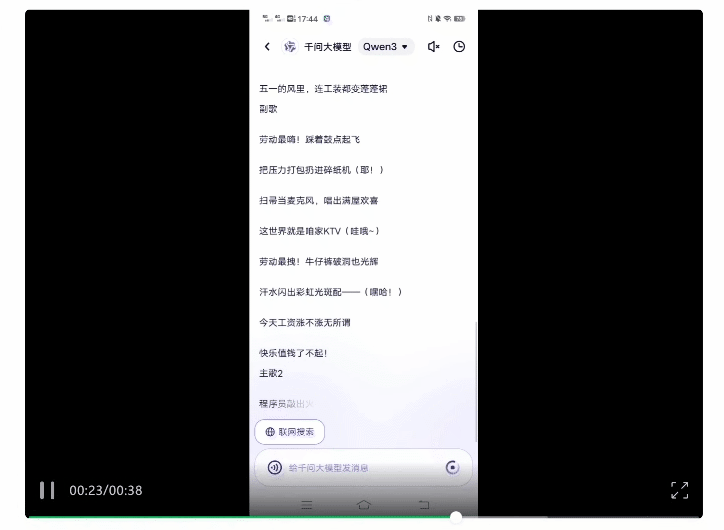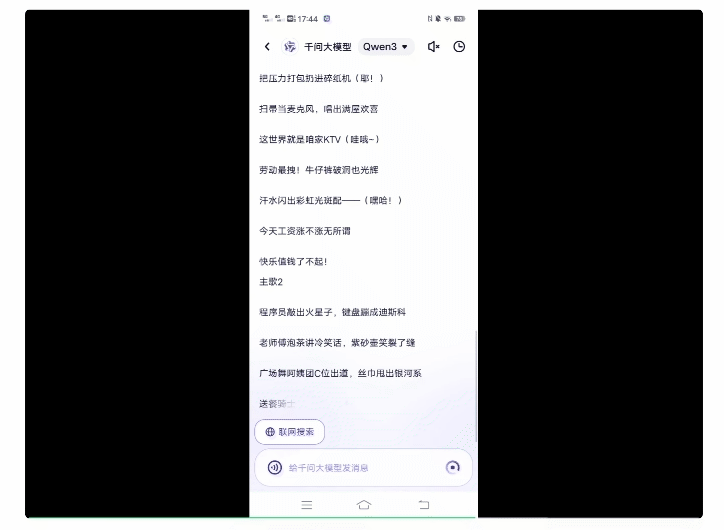
此外,最近火上热搜的“AI写歌”,我们也用Qwen3尝试了一把。
五一版·大张伟嗨歌这就新鲜出炉,光看歌词确实有内味儿了:
Okk,以上为我们的全部实测。
小结一下,通过在通义App使用Qwen3专属智能体,我们能明显感受到以下几点:
- Qwen3旗舰模型的生成速度非常快,体验很丝滑;
- 模型擅长推理,能够解决经典逻辑陷阱和复杂数学题;
- 代码能力方面,已经能够快速实现一些简单需求;
- 由于载体是App,可拓展的玩法很多。
而且,通义App自上个月页面改版后,整体设计更简洁,交互也更加完善了。
更多网友实测
与此同时,随着Qwen3模型的爆火,更多网友也第一时间进行了试玩。
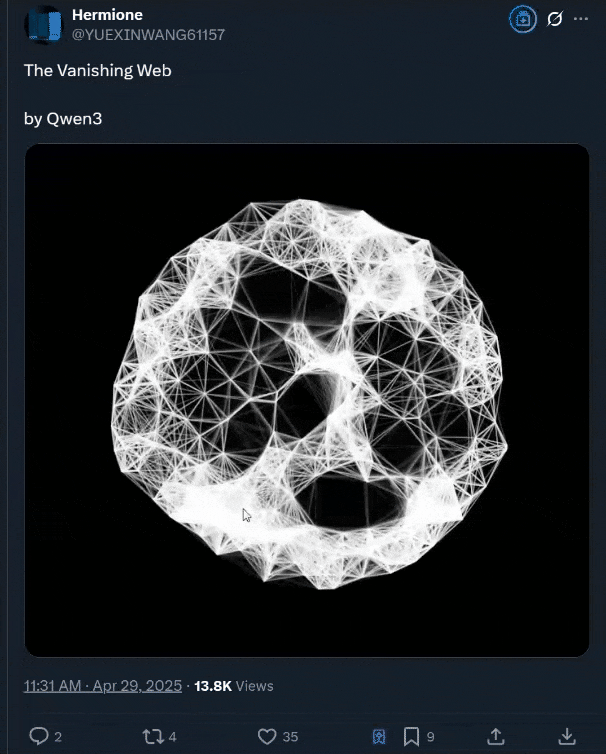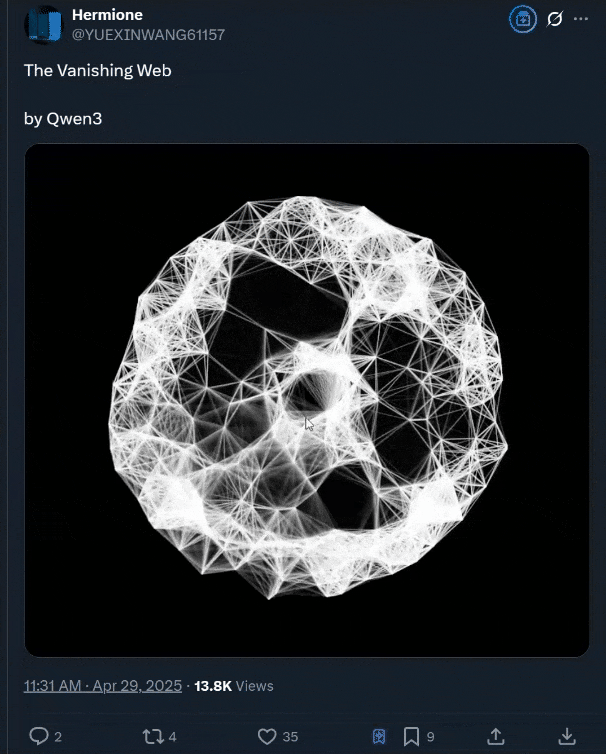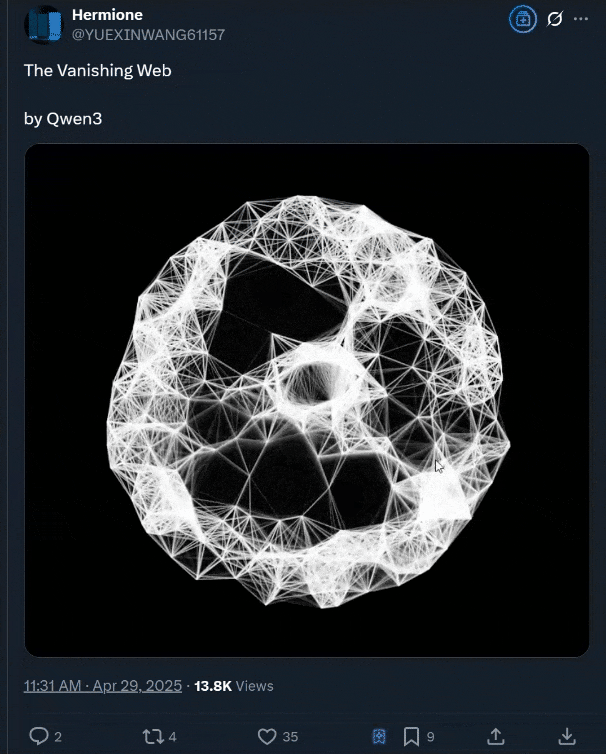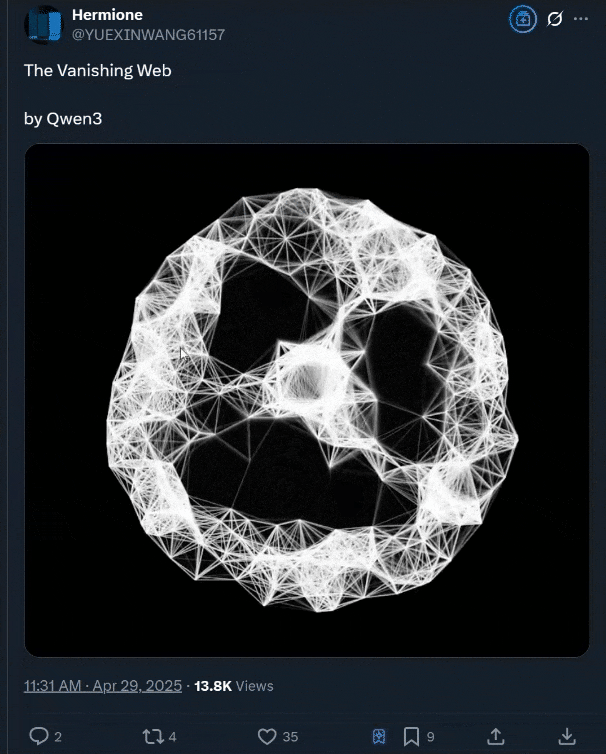
有和“空间内弹小球”类似效果的页面设计:
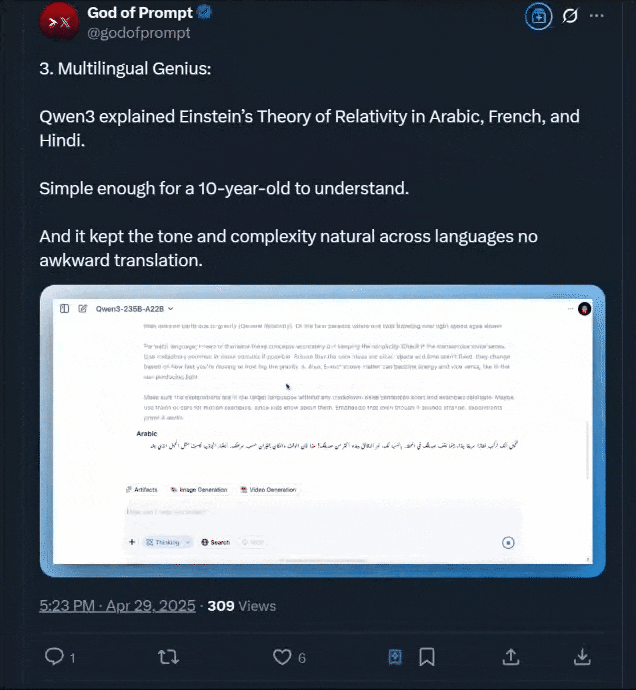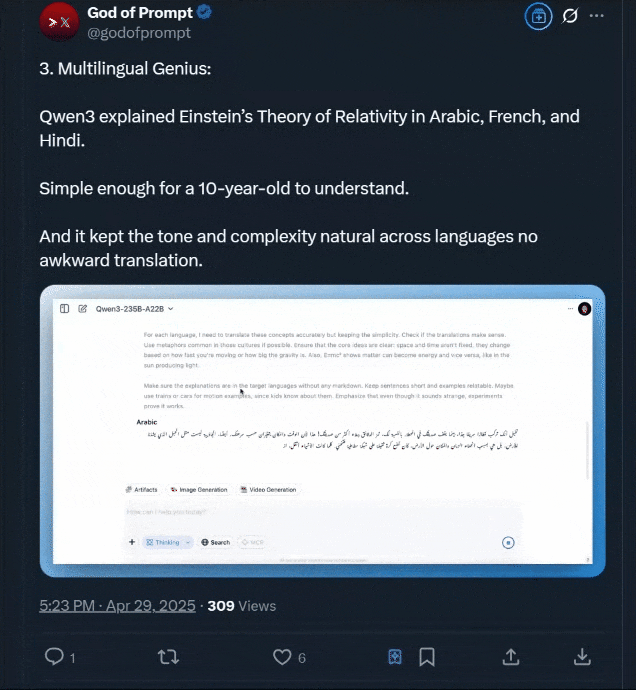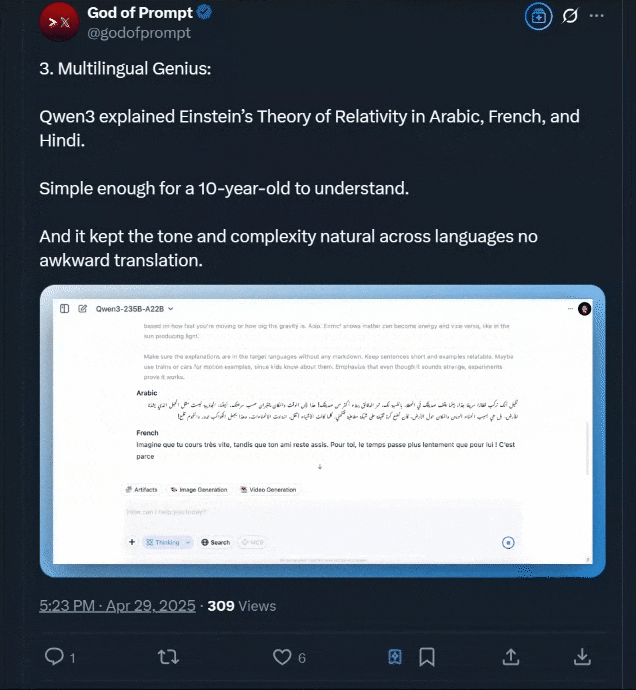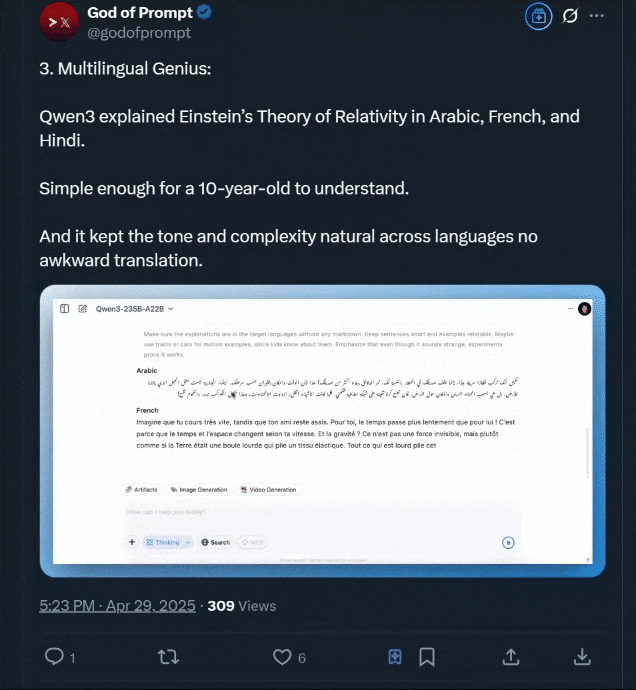
还有用阿拉伯语、法语和印地语解释爱因斯坦相对论的玩法,该博主声称:
当然,大家一直尤为钟爱的小游戏开发也安排上了:
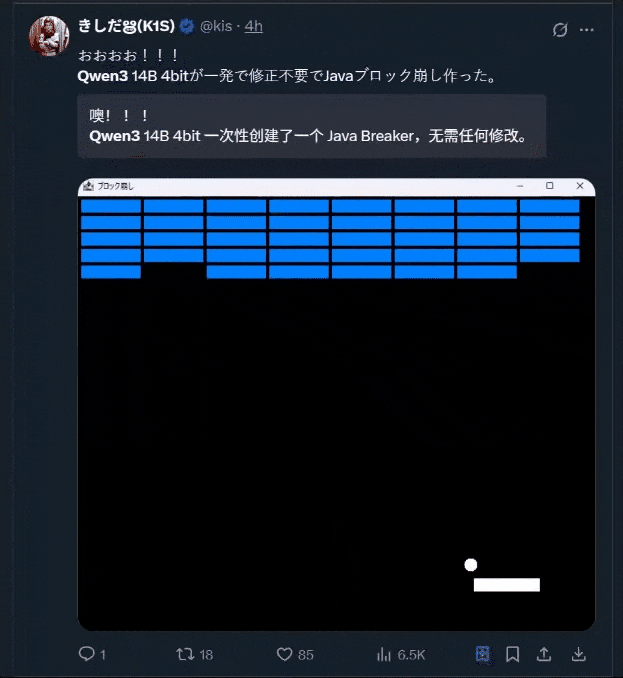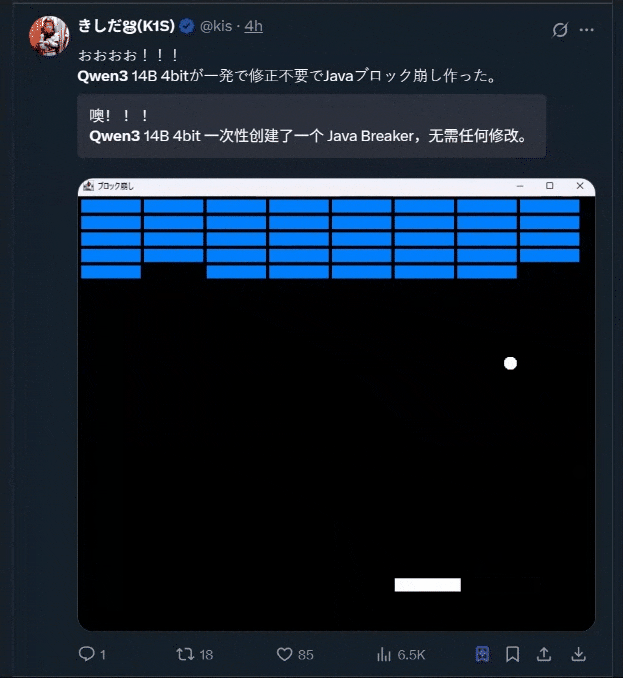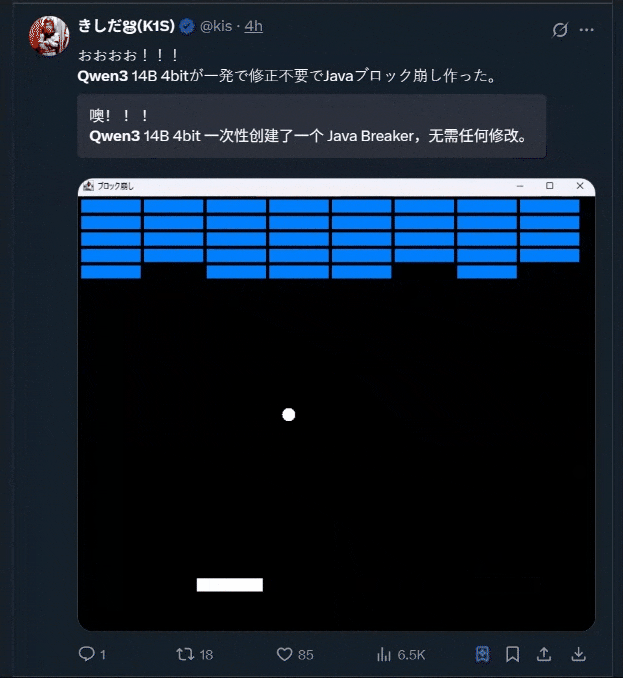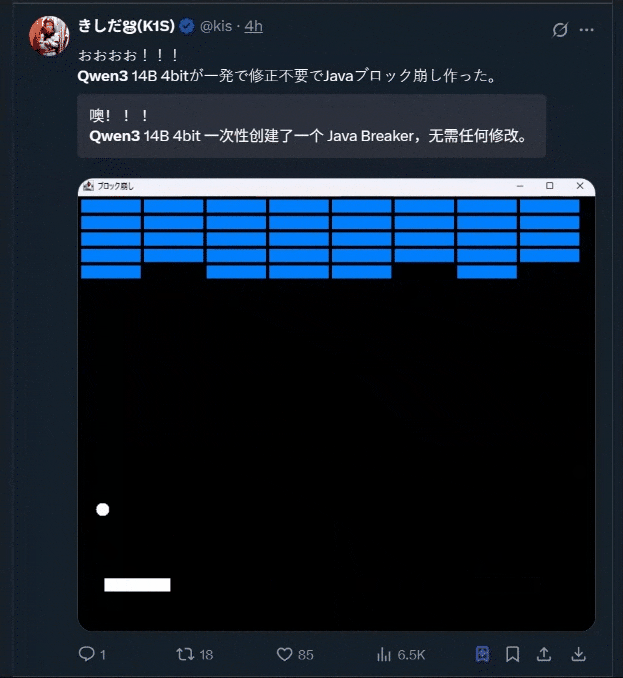
开源界的新王者
Qwen3引发热议背后,可以看到的是,在开源影响力上,以Qwen为代表的国产大模型,已经有超越Llama之势。
这一点,从reddit LocalLLaMA等开发者聚集的板块的最新话题中,亦可见一斑。
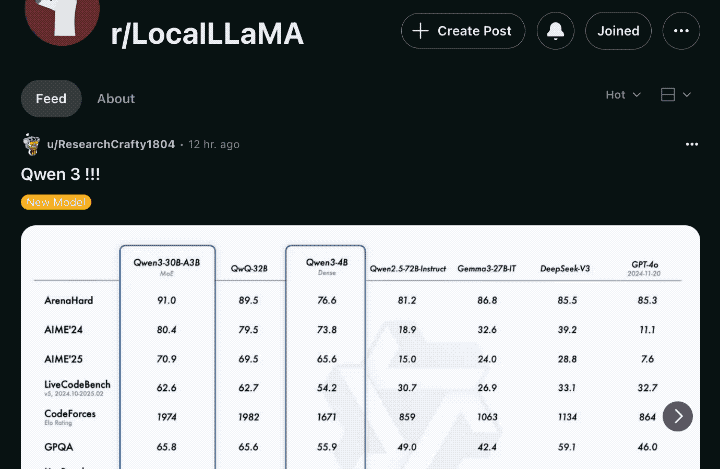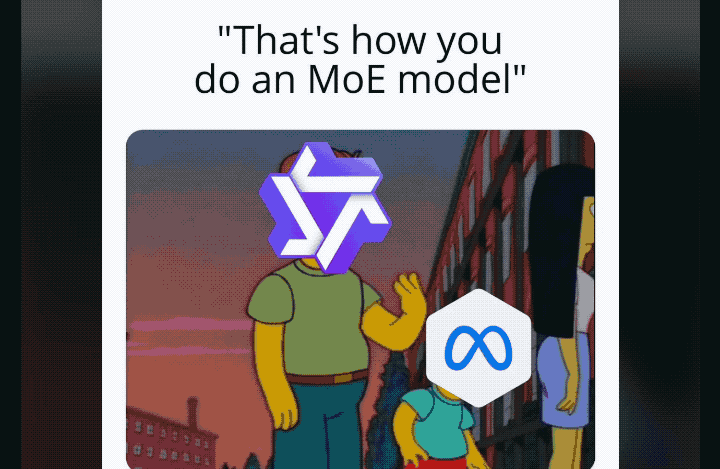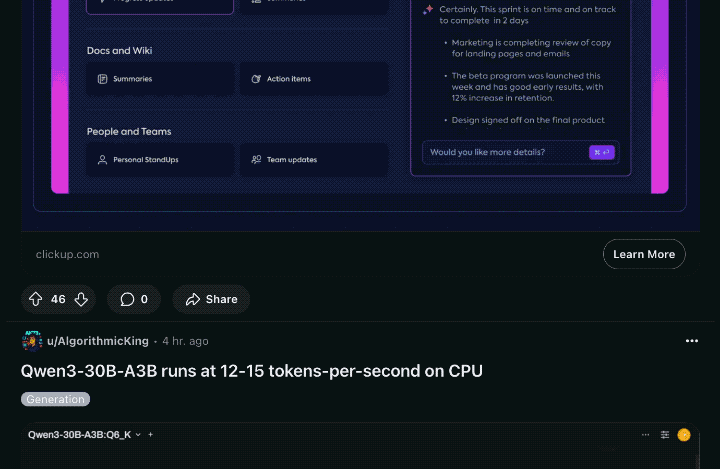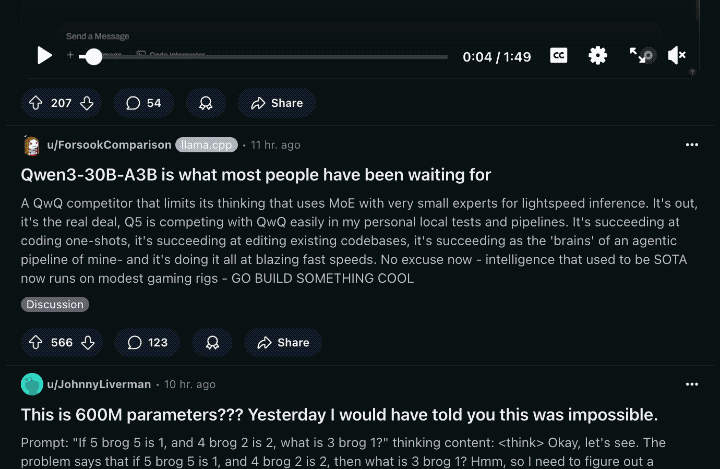
不仅是基准评测数据的纸面超越,实测越多,模型实力究竟几何就越能被客观公允地认知。
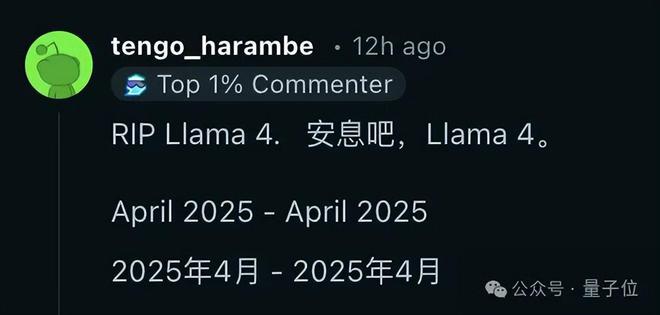
而如今的开源格局之变,并非一蹴而就。前有DeepSeek,今有Qwen3,背后体现的是来自中国的开源力量一以贯之的努力,和一如既往的“中国速度”。
以Qwen为例:
2024年11月底,开源推理模型QwQ;
2025年春节档,连发Qwen2.5百万上下文版本、视觉理解模型Qwen2.5-VL,还有超大规模MoE模型Qwen-2.5 Max;
2025年3月,QwQ-32B以1/10成本比肩DeepSeek-R1;
多模态方面,还有万相Wan的持续开源和迭代……
这还只是短短5个月内的进展。
再加上更加开放和商用友好的Apache 2.0协议,开发者们的转向,自然在情理之中。

作为普通用户,一方面,可以在通义App这样的官方应用上更快感知到满血模型的能力。
另一方面,也可以期待开源,带来更多衍生应用的可能性。
那么,再次打开传送门:
tongyi.com
如果你探索到了什么新鲜玩法,也欢迎在评论区跟大家分享~
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/9908.html