
想让手机AI像人类一样快速学习?
浙大与vivo联手突破!全新LearnAct框架仅需一次示范,就能教会AI完成复杂操作。
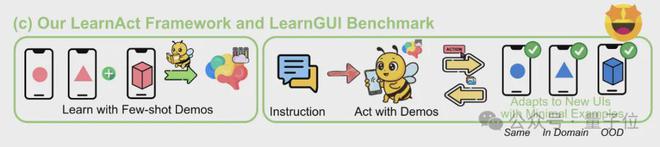

研究同步发布的LearnGUI基准,首次构建了面向移动端示范学习的评估体系,为AI智能体的实用化部署提供了关键技术支撑。
本文的作者来自浙江大学和vivo AI lab。本文的共同第一作者为浙江大学硕士生刘广义和赵鹏翔,主要研究方向为大语言模型驱动的GUI智能体技术。项目leader 为vivo AI lab 算法专家刘亮。本文的通信作者为浙江大学孟文超研究员。

手机GUI智能体:潜力与挑战并存
随着大型语言模型(LLMs)的快速发展,手机图形用户界面(GUI)智能体作为一种能够通过环境交互自主完成人类任务的前沿技术,正逐渐引发人们的关注。这些智能体通过观察手机屏幕(截图或UI Tree)感知手机状态,并生成相应的动作(如点击、输入、滑动等)来实现任务自动化。
然而,手机GUI智能体在实际部署场景中仍面临重大挑战。
移动应用和用户界面的多样性创造了许多长尾场景,截至2025年仅Google Play上就有168万个应用,现有智能体在长尾场景中难以有效执行任务。
目前主流的智能体构建方法依赖通用LLMs的内在能力或通过大量数据微调,但面对以数百万的移动应用及数十亿用户各自独特的任务需求,这些方法难以覆盖如此庞大的多样性,导致在未见场景中表现不佳,阻碍了手机GUI智能体的广泛应用。
从「示范中学习」的新范式
为解决上述限制,浙江大学和vivo AI lab联合提出了LearnAct多智能体框架LearnGUI基准致力于通过「少样本示范学习」解决手机GUI智能体的「长尾问题」。
与传统方法不同,这种基于示范的方法能够在少量用户提供的示例基础上实现稳健性和个性化,从而弥合预训练模型无法覆盖的“个性化鸿沟”。
实现结果表明,单个示范就能使Gemini-1.5-Pro的准确率从19.3%提升至51.7%,UI-TARS-7B-SFT的在线任务成功率从18.1%提升至32.8%。LearnAct多智能体框架和LearnGUI基准的提出为设计更加智能、更加个性化的手机 GUI 智能体开辟全新的方向,让我们的手机操作变得更加便捷、高效。
△LearnAct多智能体框架和LearnGUI基准致力于通过少样本示范学习解决手机GUI智能体的长尾问题

研究团队认识到,手机用户通常有独特且重复性的任务,同时具有内在变化性——例如智能家居控制、健康监测或企业软件。
这些场景结合了稳定模式和可变元素,通过用户特定的示范,该方法使智能体能够学习一致模式和适应策略,获取一般训练数据集无法覆盖的任务特定知识。
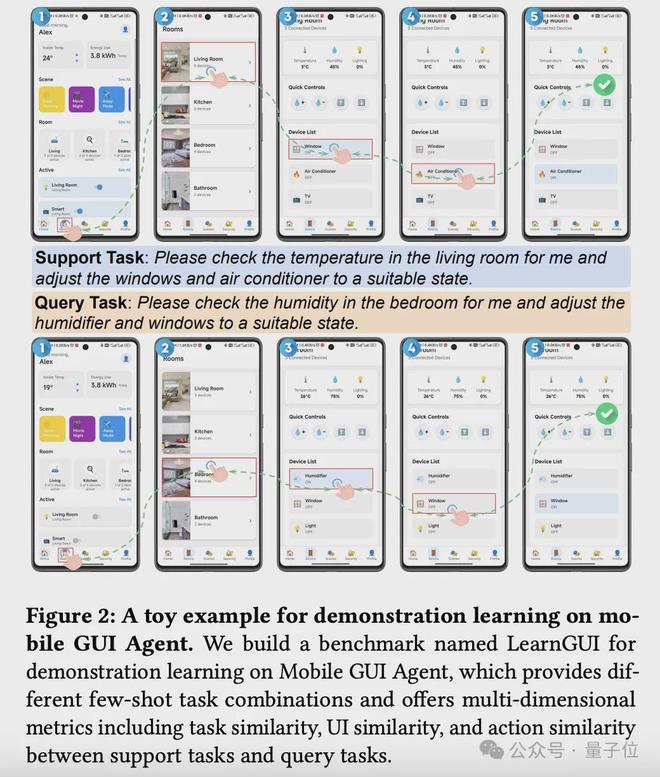
△LearnGUI数据集示例
LearnGUI:首个专为研究示范学习设计的基准
为填补高质量示范数据的空白,研究团队构建了LearnGUI基准。
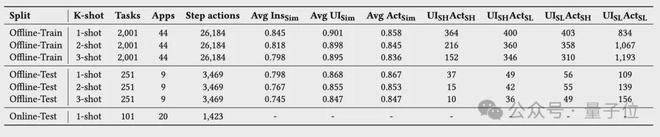
这是首个专为研究移动 GUI 代理从少量示范中学习能力而设计的基准。基于AMEXAndroidWorld构建,LearnGUI 包含 2,252 个离线少样本任务和 101 个在线任务,均附带高质量人类示范。
△LearnGUI基准基本信息
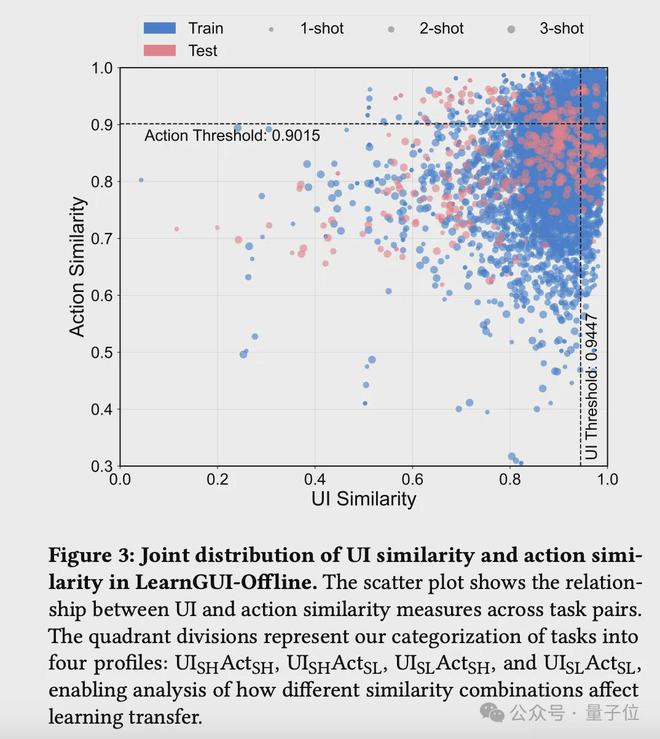
该基准不仅支持对不同数量示范对代理性能影响的研究,还系统分析了示范任务与目标任务之间不同类型相似性(指令相似性、UI 相似性和动作相似性)对学习效果的影响。
△LearnGUI基准中的示范任务数量以及与目标任务相似度的分布情况
LearnAct:多智能体框架自动理解和利用示范
研究团队进一步提出了LearnAct多智能体框架,能够自动理解人类示范、生成指导性知识,并使用这些知识帮助手机GUI智能体推理未见场景。LearnAct由DemoParser、KnowSeeker和ActExecutor三个专业智能体组成。
△LearnAct框架的三个核心组件:DemoParser、KnowSeeker和ActExecutor
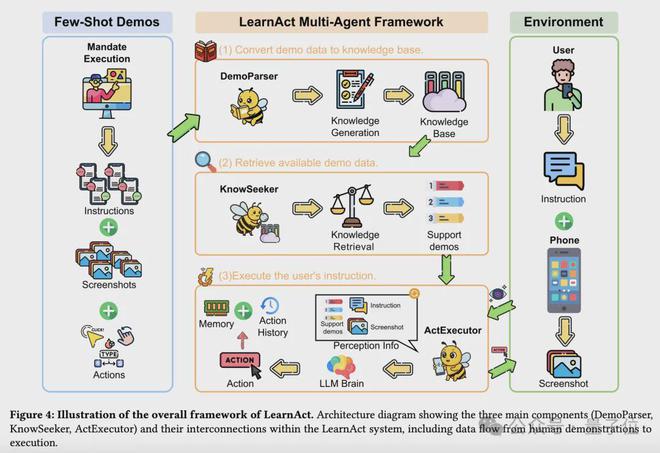
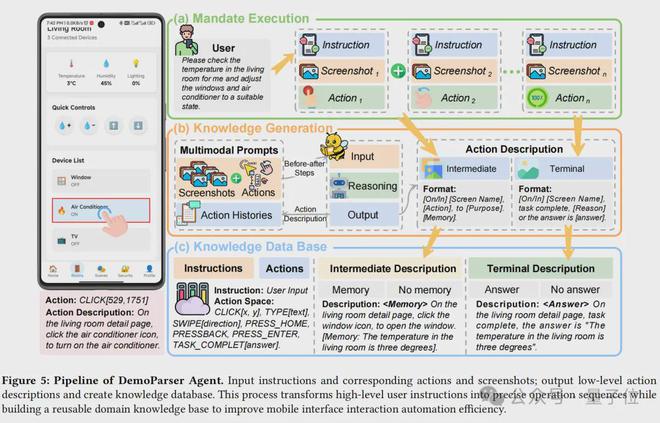
DemoParser智能体将原始的人类示范转化为结构化的示范知识。
它以原始动作序列(包括基于坐标的点击、滑动和文本输入等)以及相应的屏幕截图和任务指令作为输入。
随后,它利用视觉-语言模型生成具有语义描述性的动作描述,捕捉每个演示步骤的本质(例如,“在搜索页面上,点击搜索框,输入关键词”)。
基于这些描述,它构建了一个结构化的知识库,记录了高层次的动作语义。
△DemoParser工作流
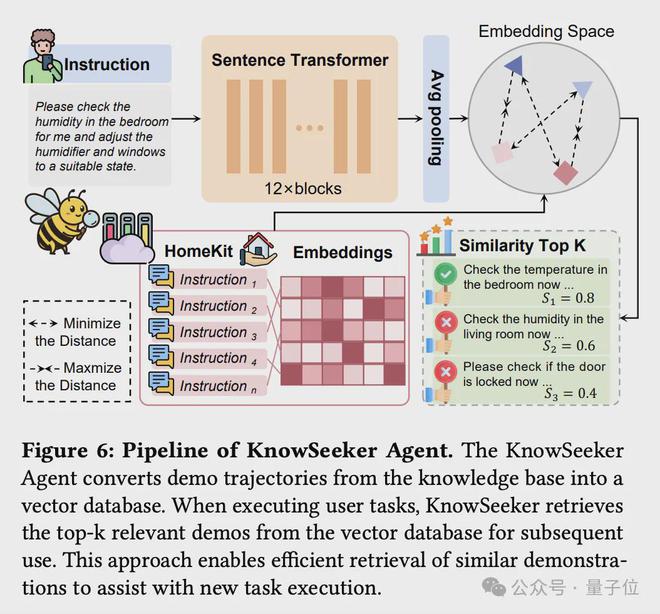
KnowSeeker智能体是LearnAct框架中的检索组件,负责识别与当前任务上下文最相关的演示知识。
KnowSeeker充当由DemoParser生成的知识库与ActExecutor执行环境之间的桥梁,专精于高效地访问和选择针对特定任务最适用的知识。
△KnowSeeker工作流程
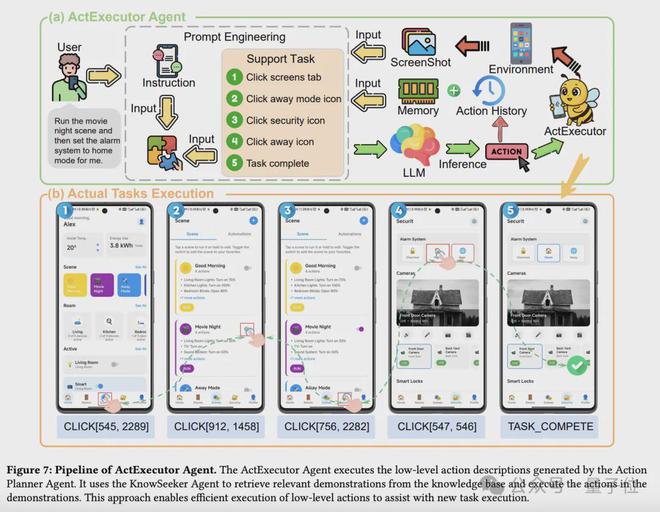
ActExecutor智能体是LearnAct框架中的执行组件,它将检索到的演示知识转化为目标环境中有效的操作。
ActExecutor是LearnAct流程的最终环节,它整合了用户指令、实时的图形用户界面感知信息以及演示知识,能够熟练的操作长尾场景下的手机界面。
当DemoParser创建结构化知识,而KnowSeeker检索到相关的演示后,ActExecutor则运用这些知识来解决实际任务。
△ActExecutor工作流
这种多智能体架构使LearnAct能够系统地从人类示范中提取、检索和利用知识,通过最少的示范实现对新场景的有效适应。
实验结果:示范学习显着提升性能
实验结果揭示了示范学习对手机GUI智能体能力的显着增强。
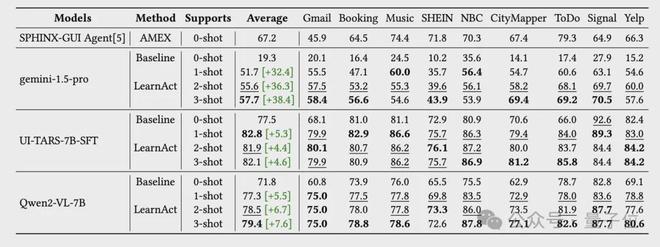
在离线评估中,单个示范就能大幅提升模型性能,最引人注目的是Gemini-1.5-Pro的准确率从19.3%提升至51.7%(相对提升198.9%)。
在复杂应用如CityMapper和To-Do应用中,性能提升尤为明显,分别从14.1%提升至69.4%和从17.4%提升至69.2%。
△不同模型在LearnGUI-Offline基准上的性能比较
在真实世界的在线评估中,LearnAct框架表现出色。
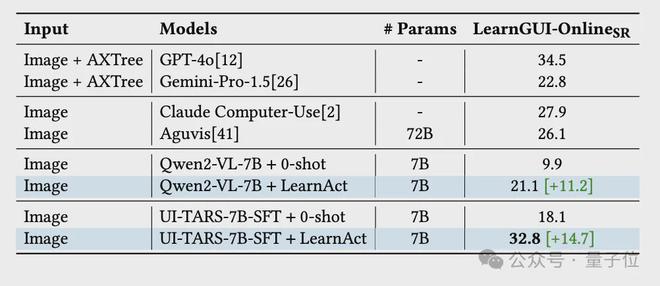
下表展示了在LearnGUI-Online基准上的在线评估结果,LearnAct 框架显着提升了所评估的两种模型的性能,其中 Qwen2-VL-7B从 9.9% 提升至 21.1%(+11.2%),UI-TARS-7B-SFT从 18.1% 提升至 32.8%(+14.7%)。
这些显着的提升表明,基于示范的学习方法能够有效地转化为现实交互场景中的优势。
△不同模型在LearnGUI-Online基准上的性能比较
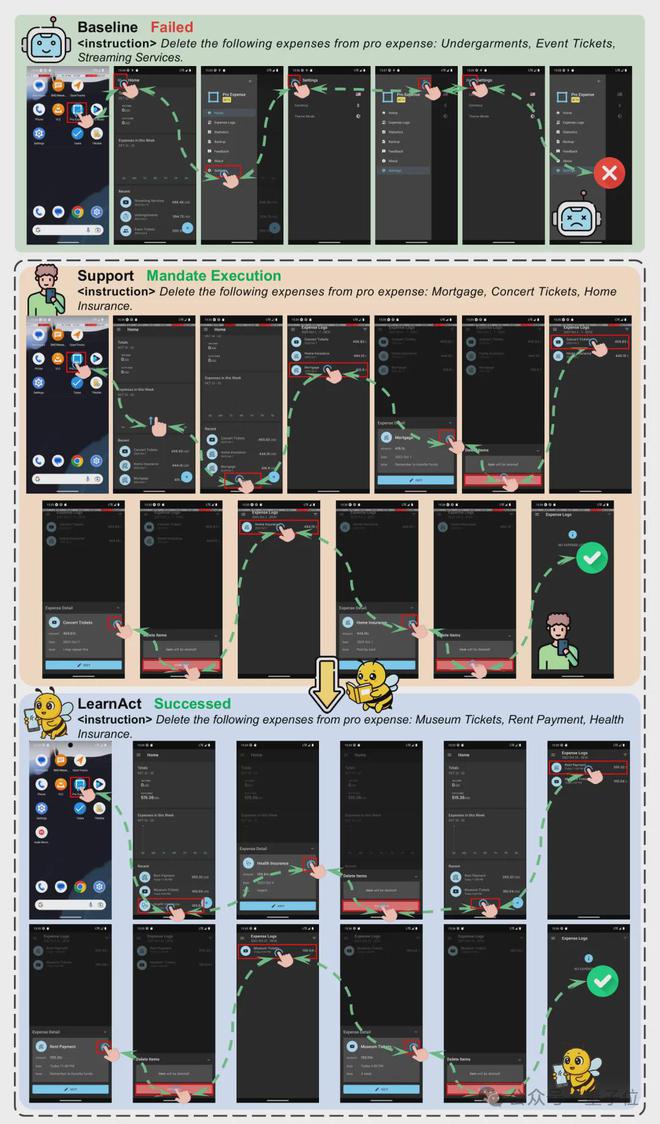
下图中给出了LearnAct和Baseline方法在ExpenseDeleteMultiple任务上的表现。
在这样的长尾场景下,Baseline方法中GUI 智能体无法正确规划任务执行路径最终以失败告终。
相比之下只需要给出一个演示案例,LearnAct框架就能自动识别ExpenseDeleteMultiple任务中的执行模式并进行学习,面对相似的任务与不同的UI界面,顺利完成了操作任务。
△Qwen2-VL-7B作为基模型,LearnAct和Baseline在ExpenseDeleteMultiple任务上的表现
结论:示范学习引领手机GUI智能体发展新方向
这项研究提出的基于示范学习的新范式,为应对手机GUI智能体的长尾挑战开辟了新路径。
作为首个全面的示范学习研究基准,LearnGUI与LearnAct多智能体框架,有力证明了示范学习在开发更具适应性、个性化和实用性的手机GUI智能体方面的巨大潜力。
随着移动设备在现代生活中的广泛应用,这种能够从少量示范中高效学习的方法,为打造真正智能的手机助手奠定了坚实基础,让我们在现实世界中距离科幻电影中“J.A.R.V.I.S.”般的智能体验更近一步。
论文地址:
https://arxiv.org/abs/2504.13805
项目地址:
https://lgy0404.github.io/LearnAct/
GitHub:
https://github.com/lgy0404/LearnAct
HuggingFace:
https://huggingface.co/datasets/lgy0404/LearnGUI
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/10228.html