
DeepSeek放大招!新模型专注数学定理证明,大幅刷新多项高难基准测试。
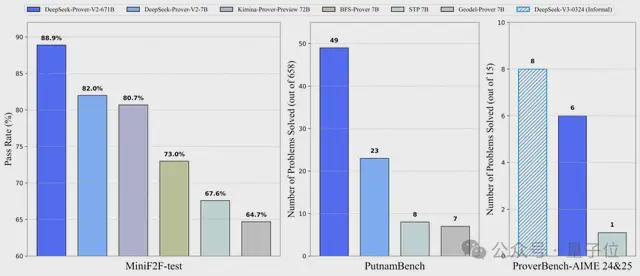
在普特南测试上,新模型DeepSeek-Prover-V2直接把记录刷新到49道。
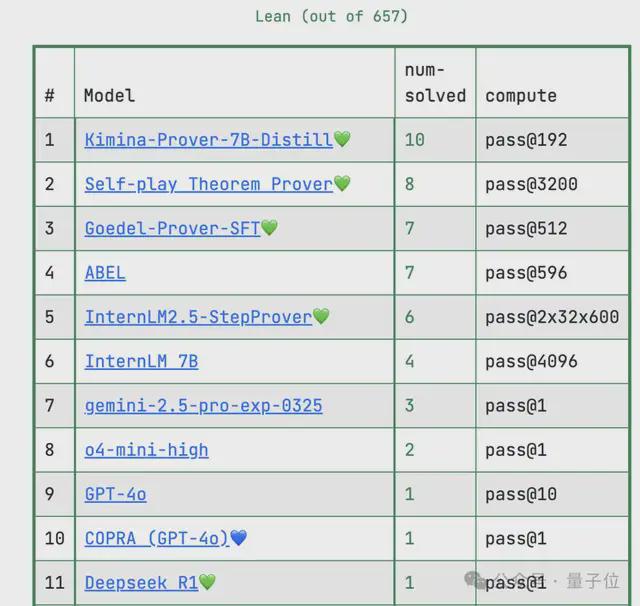
目前的第一名在657道题中只做出10道题,为Kimi与AIME2024冠军团队Numina合作成果Kimina-Prover。
而未针对定理证明优化的DeepSeek-R1只做出1道。
让还没发布的R2更令人期待了。

除测评结果之外,论文中特别报告了“通过强化学习发现新技能”现象。
正如R1带来了“啊哈时刻”,Prover-V2也有令人意想不到的能力。

具体来说,在普特南测试中,参数量较小的DeepSeek-Prover-V2-7B用非CoT生成模式成功解决了13个671B模型未能解决的问题。
团队仔细检查该模型的输出后发现,其推理方法存在一个独特模式:7B模型处理涉及有限基数的问题时,经常使用Cardinal.toNat和Cardinal.natCast_inj,而671B模型生成的输出中明显没有这些内容。
要注意,7B模型是在DeepSeek-Prover-V1.5-Base模型基础上,先使用671B模型在强化学习阶段收集的数据微调,再执行强化学习得来的。
也就是说,7B模型学会了671B模型没有学会的新技能。

那么,DeepSeeK-Prover-V2如何炼成的呢?与前代相比又有哪些改进?
形式化和非形式化数学证明统一模型
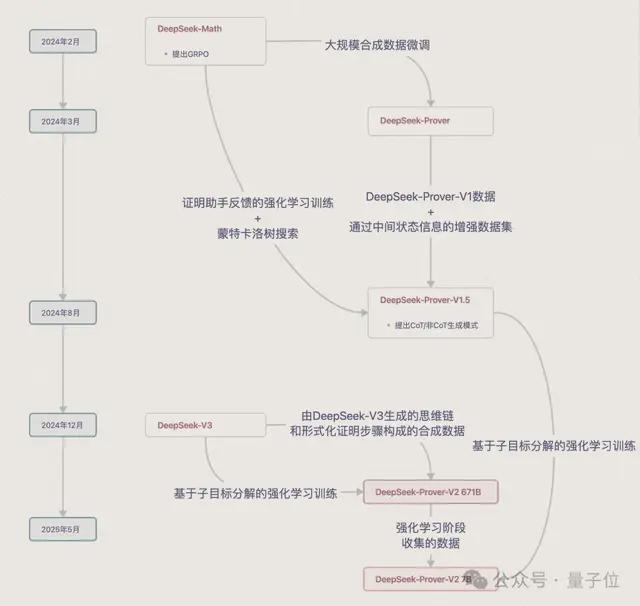
DeepSeek数学定理证明DeepSeek-Prover系列模型已推出3款:
- 2024年3月的DeepSeek-Prover(后简称为Prover-V1)
- 2024年8月的DeepSeek-Prover-V1.5(后简称为Prover-V1.5)
- 2025年5月的DeepSeek-Prover-V2(后简称为Prover-V2)
Prover-V1主要探索了通过大规模合成数据集微调DeepSeek-Math-7B,来推进定理证明。
Prover-V1.5在此基础上增加了证明助手反馈的强化学习(RLPAF)和蒙特卡洛树搜索方法。
Prover-V2进一步提出“子目标分解的强化学习”,并且基础模型从DeepSeek-Math-7B升级到DeepSeek-V3。
整合DeepSeek-V3的高上下文窗口和强大的自然语言推理能力,把形式化和非形式化数学证明统一到一个模型中。
Prover-V2还继承了Prover-V1.5提出的CoT和非CoT生成两种模式。
接下来,详细介绍Prover-V2的各主要环节。
通过递归证明搜索合成冷启动推理数据
利用DeepSeek-V3作为子目标分解和形式化的统一工具构建冷启动数据集,提示DeepSeek-V3将定理分解为高级证明草图,同时在Lean 4中将这些证明步骤形式化,从而产生一系列子目标。
使用一个较小的70亿参数模型来处理每个子目标的证明搜索,从而减轻相关的计算负担。一旦一个具有挑战性的问题的分解步骤得到解决,就将完整的逐步形式化证明与来自DeepSeek-V3的相应思维链进行配对,以创建冷启动推理数据。

使用合成冷启动数据进行子目标分解的强化学习
团队精心挑选了一组具有挑战性的问题,这些问题无法由70亿参数量的证明器模型以端到端的方式解决,但所有分解后的子目标都已成功解决。
通过组合所有子目标的证明,为原始问题构建了一个完整的形式化证明。
然后,将此证明附加到DeepSeek-V3的思维链中,该思维链概述了相应的引理分解,从而实现了非形式化推理与后续形式化的有机结合。
在合成冷启动数据上对证明器模型进行微调后进行强化学习阶段,进一步增强其将非正式推理与形式化证明构建相衔接的能力。遵循推理模型的标准训练目标,使用二元的正确或错误反馈作为奖励监督的主要形式。

具体训练细节
两阶段训练:
DeepSeek-Prover-V2分两阶段建立互补证明生成模式。
第一阶段用高效非思维链(non-CoT)模式,聚焦快速生成Lean证明代码,加快迭代和数据收集。
第二阶段基于第一阶段成果,采用高精度思维链(CoT)模式,阐述中间推理步骤,用冷启动思维链数据强化学习,提升复杂问题推理能力。
专家迭代:
其中非CoT模式训练遵循专家迭代范式,用最佳证明策略为难题生成证明尝试,经Lean验证,成功的纳入监督微调(SFT)数据集。与之前版本相比,训练问题分布有调整,引入了额外问题和子目标分解生成的问题。
监督微调:
对DeepSeek-V3-Base-671B做监督微调,训练语料库包含两个互补来源的数据:
一是通过专家迭代收集的非CoT数据,这些数据生成的Lean代码不包含中间推理步骤,主要用于强化模型在 Lean 定理证明生态系统中的形式验证技能。
二是冷启动CoT数据,这些数据将DeepSeek-V3的先进数学推理过程提炼为结构化的证明路径,明确地模拟了将数学直觉转化为形式证明结构的认知过程。
强化学习:
采用GRPO算法,与传统的PPO不同,GRPO无需单独的裁判模型,它通过为每个定理提示采样一组候选证明,并根据它们的相对奖励来优化策略。
训练过程中使用二元奖励机制,即生成的Lean证明若被验证正确则获得奖励1,否则为0。
为确保学习效果,精心挑选训练提示,仅包含那些有足够挑战性但又能被监督微调后的模型解决的问题。
蒸馏DeepSeek-Prover-V2 7B
将DeepSeek-Prover-V1.5-Base-7B上下文窗口扩展到32768个token,用DeepSeek-Prover-V2-671B数据微调,融入非CoT证明数据,以便利用小模型生成简洁的形式化输出,提供一种经济高效的证明选项。
此外,对DeepSeek-Prover-V2-7B执行与671B模型训练中相同的强化学习阶段,以进一步提升其性能。
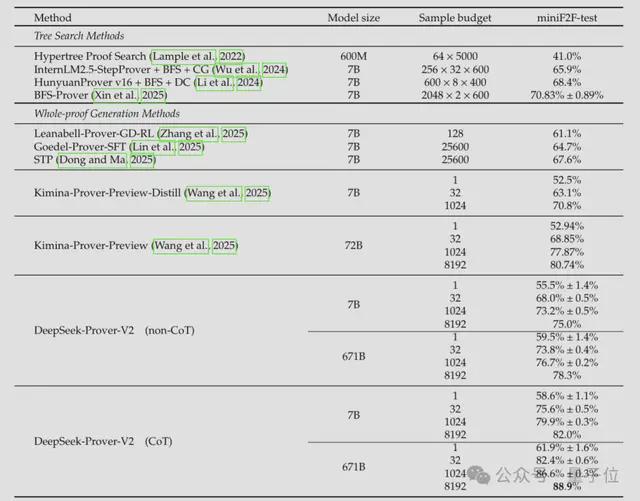
由此得到的模型Prover-V2 671B在神经定理证明方面达到了最先进的性能,在miniF2F测试中的通过率达到 88.9%,并解决了普特南测试中的49道。Prover-V2为miniF2F数据集生成的证明可单独下载。
ProverBench:AIME和教科书问题的形式化
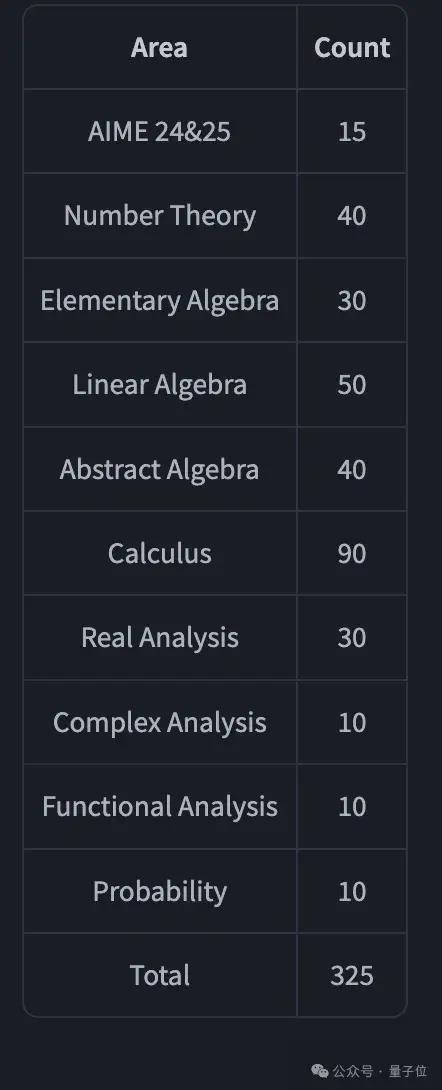
与Prover-V2一起推出ProverBench,这是一个包含325个问题的基准数据集。其中,有15个问题是从近期美国数学邀请赛(AIME 24和25)的数论与代数题目中形式化而来,提供了真实的高中竞赛水平挑战。其余310个问题则取自精心挑选的教科书示例和教学教程,构成了一套多样化且基于教学需求的形式化数学问题集合。该基准旨在能够对高中竞赛问题和本科阶段数学问题进行更全面的评估。
DeepSeek-Prover-V2系列在三个数据集上评测的最后总成绩如下:
DeepSeek全明星阵容
Prover-V2的作者共18人,共同一作Z.Z. Ren, 邵智宏、辛华剑都是参与过V3、R1以及Prover系列前作的主力成员。

作者名单中出现了几位未参与前两代版本(Prover-V1、Prover-V1.5)的研究者。
比如Shirong Ma,清华本硕。公开资料显示,他于去年毕业后即加入DeepSeek,现为DeepSeek研究员,此前参与了从DeepSeek LLM v1到R1以及DeepSeek-Coder等工作。

还有Zhe Fu、Yuxuan Liu。
虽然他们都没出现在Prover-V1、Prover-V1.5的作者名单中,但均为DeepSeek资深成员。
在Prover-V1/V1.5同一期发布的《Fire-Flyer AI-HPC》研究中可见其署名。

该研究提出的Fire-Flyer AI-HPC架构,通过软硬件协同设计降低训练成本,解决传统超算架构在AI训练需求上的不足。
不过这次Prover-V2的论文中并未提及在训练或推理基础设施具体有哪些优化策略。
最后还有一位新面孔Hongxuan Tang,暂未了解到具体信息。
Prover-V2发布后迅速引发社区关注,GitHub仓库12小时内即获得350+星标。
在X(原Twitter)、抱抱脸等平台,网友们展开热烈讨论。
Prover-V2核心贡献者邵智宏在个人账号主动推介研究成果。
X工程师@kache特别赞赏道:

普林斯顿大学助理教授Chi Jin表示:

就连Kimina-Prover核心贡献者@Marco Dos Santos都来送上了祝贺:

另外,网友们最关注的问题仍然是:R2什么时候发布啊~


论文:
https://github.com/deepseek-ai/DeepSeek-Prover-V2/blob/main/DeepSeek_Prover_V2.pdf
模型:
https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B
DeepSeek-Prover
https://arxiv.org/abs/2405.14333
DeepSeek-Prover-V1.5
https://arxiv.org/abs/2408.08152
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/10208.html