
当大模型赛道中不少玩家明确表示放弃基础大模型研发,心思放在更聚焦的方向上时,阶跃星辰站出来——就像这家公司第一次亮相时那样,给外界一个明确的回答:
创始人兼CEO姜大昕解释了背后逻辑。
一方面,大模型行业的趋势技术发展还是在非常陡峭的区间。他也很感慨AI行业发展瞬息万变,“去年大家觉得GPT-4很牛,今天他都快下架了”,等到明年看今年的技术,同样会觉得微不足道。
姜大昕说,阶跃不想在这个过程中放弃主流增长或前进的趋势,所以还是会坚持做基础模型的研发。


另一方面,从应用的角度来看,阶跃仍然相信应用和模型是相辅相成的。
“模型可以决定应用的上限,应用给模型提供具体的应用场景和数据。”姜大昕表示,虽然阶跃的产品形态随着模型的演变是动态发展的,但这样的逻辑关系还是一直保持下去的。
确实如他所说,在过去的一年里,阶跃星辰旗下产品从命名、布局和形态上都发生了转变。
主打的C端助手App,由“跃问”改名为“阶跃AI”,意味着它从类ChatGPT产品到Agent的转变;产品重点形态从用户普遍直接使用的手机App变成了端云一体Agent平台。
“虽然我们的智能终端Agent和头部企业合作,但总体而言,阶跃的产品最终是服务C端的。”姜大昕表示,“不管作为助手类也好、内容类也好,都有非常大的机会。”
大模型领域的两条显着趋势
姜大昕同时强调,模型的突破是早于商业化的。就拿OpenAI来说,是先有了GPT-3.5,才有了ChatGPT。
因此,在基座模型上面继续投入以追求智能的上限,仍然是当下最重要的一件事。
要怎么去不停触碰智能的边界or天花板?不如先来看看这个领域里最前沿的趋势有哪些。
姜大昕复盘道,趋势共有如下两条:
一条是“模仿学习到强化学习”,另一条是“从多模态融合走向了多模态理解生成一体化”。
从模仿学习到强化学习的技术演进大家已经非常熟悉, OpenAI的o1、o3,以及DeepSeek-R1背后采用的都是强化学习技术,也是现在大模型玩家争先恐后着重投入的方向。
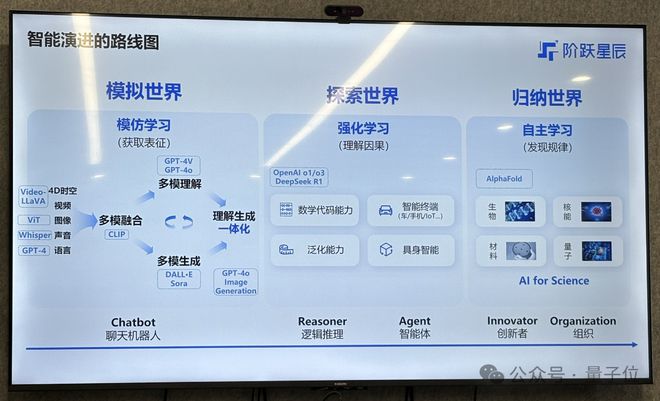
第二条趋势则关乎多模态。
姜大昕再次提到了那句他在多个场合不停重复提及的话:多模态是实现AGI的必经之路。
无论是从人类智能的多元化角度(符号智能、视觉智能、空间智能等),还是从垂直领域AI应用需求来说,大模型的多模态能力都必不可少。
在这样的认知指导下,阶跃星辰在研发基座模型时采取了散弹式打法:
成立两年,公司累计发布22款基座模型,覆盖文字、语音、图像、视频、音乐、推理等系列。
其中有16款是多模态模型,占据总数七成;这些多模态模型又分属图像理解、视频理解、图像生成、视频生成、图像编辑、音乐生成、多模态推理等方向。
业界公认阶跃是多模态卷王,也不是没有道理。
多模态理解生成一体化才是未来
至于如何追求智能的上限,阶跃目前行进的路线与第一次公开亮相时所讲的那样一般无二,即“单模态——多模态——多模态理解和生成的统一——世界模型——AGI”。
姜大昕重点解释了关于“多模态理解生成一体化”的部分。
它意味着多模态模型的理解和生成用一个模型来完成,而不是“视频/图像/语言转文本——文本理解与生成——生成结果转视频/图像/语音”的三段式过程。
大语言模型的理解生成一体化,已经有类GPT实现统一;然而在视觉领域并不如此,人们往往在理解视觉内容时选择一个模型,在生成内容时调用另一个模型。
这并不是一个可以直接从语言模型的NTP(Next-Token-Prediction)直接迁移到视觉模型的NFP(Next-Frame-Prediction)的简单事。
语言文本模态是低维度离散分布的,而视觉模态是高维度连续分布,这也就是说后者在进行训练学习时,复杂性更高。

从技术角度来看,视觉领域的内容生成需要理解来控制——如果想保证生成内容有意义、有价值,实际上需要对视觉的“上下文”作出更好的理解。
反言之,理解需要生成来监督。姜大昕解释说,就是“只有生成了的时候才是真正的理解了”。
现在,视觉领域还没有出现自己的Transformer架构,阶跃就是想做出一个视觉领域的、生成一体化架构,并且是非常scalable的。
姜大昕分享道,GPT-4o可能已经实现了多模态理解生成一体化,而阶跃的图像编辑模型Step1X-Edit也初步实现了这一点。
之所以称其为“初步”,是阶跃觉得Step1X-Edit的效果依然有很大改进空间,还可以在架构上做进一步的优化,数据上也可以做进一步的打磨,让它的效果变得更好一些。
但具体走哪条路线能精益求精,不管是阶跃内部还是业界都没有公认的真理。姜大昕表示,在这一方面,阶跃内部多有条技术路线并行,因为确实哪一条路线都会有可能出现突破。
“一旦突破以后,今后的道路会更加顺畅。”姜大昕称。
One More Thing
既然认可多模态理解生成一体化才是未来,为什么阶跃不把所有的精力集中在Step-R1-V-Mini这样的多模态推理模型上,反而是要在各个模态上都发力呢?
量子位把这个问题抛给了姜大昕。
他很坦然,表示也想过做,但这行不通
简单点说,做理解生成一体化,必须自身具备非常强的综合实力
但姜大昕信心满满,“我们几条线的能力都非常强,所以才可以组合起来去探索这个路径”。
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/12175.html