
OpenAI模型命名混乱没规律,以至于打开ChatGPT后,好多人都不知道到底该用哪个模型来完成任务。
不过别慌,现在咱们有救了!
刚刚,大神卡帕西在上发布了一篇使用ChatGPT时的模型选择指南。
简明扼要,一看就懂——再也不用迷茫了,再也不用在各个模型之间反复横跳试探了。


先简单回顾一下前情提要:
一直以来,OpenAI对自家模型的命名都很迷。
有GPT系列,先出了GPT-4.0,GPT-4.5,又回过头来出了GPT-4.1;有o系列,既有o1、o3、o4,结果又有4o。
模型越来越多,选择恐惧症也越来越多——
简单问题怕杀鸡用牛刀,复杂任务又怕模型智商不够……
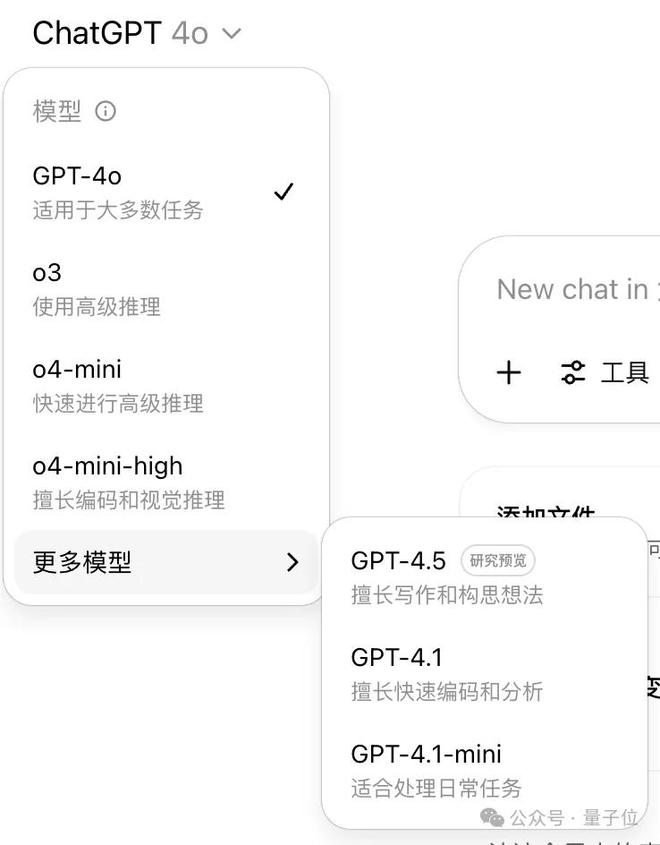
这次,卡帕西根据自己的使用习惯,把“什么时候选什么模型”梳理了一遍。
一张图解决选择恐惧症
一上来,卡帕西就明说,他知道很多人都还不知道o3、o4和4o各自的长处是什么。
他用大白话简单介绍了一下它们的区别——
其中,o3是一个比4o更强的推理模型,绝对适合任何一个重要、复杂的任务。
至于4o和o4,前者适合用来解决日常生活中中低难度的问题;o4目前只提供了mini形式,效果不如o3。
卡帕西小声吐槽,“我也不懂为什么OpenAI会在现在推出o4”。

接着,卡帕西又拿自己的日常使用场景作为展示,告诉大家啥时候该选哪个模型。
所有简单的日常问题,选GPT-4o准没错。
比如问“哪些食物富含纤维”之类的问题,大家可以放心大胆用4o。使用ChatGPT时,卡帕西40%的场景都选用这个模型。
所有复杂困难或比较重要的问题,重要到你愿意等模型思考一会儿,那就选OpenAI o3吧!
卡帕西有40%的时间都用的是o3,模型可以较好地帮忙解决“帮我理解这个税务问题”之类的活。
在敲代码的时候,想让模型帮忙完善或改进一下,GPT-4.1会是你的得力助手。
这里值得注意的一点,是让ChatGPT帮忙修改或完善代码,而不是让AI帮忙从头编写程序。
最后,当你想深入理解一件事,希望ChatGPT查看n多链接,并总结,最好的选项就是深度研究。
卡帕西在此处写了个小tips:
请注意,深度研究不是让你从模型菜单中选择某个版本的模型,而是对话框中的一个选项开关。
如果你嫌记文字太麻烦,卡帕西还贴心附上了一张图。
欢迎大家收藏,便于查询使用~

评论区有人发了另一张图(如下),简而言之就是“图快选4o,研究选o3,创作选4.5”。
卡帕西热情点赞,说差不多就是这样用的!

最后,卡帕西表示以上只是他在使用ChatGPT时总结出来的经验。
事实上,根据不同的任务和研究兴趣需要,ChatGPT、Claude、Gemini、Grok和Perplexity轮番上阵,有多位AI帮他打下手。
“选错模型不会完蛋,放弃思考才会完蛋”
卡帕西的ChatGPT模型指南发布后,立马进不少人的收藏夹(吃灰)。
有人调侃,这篇指南其实可以用一句话总结:
Reasoning is all you need.
不过并不是所有人都会充值成为Plus或者Pro会员,所以o4-mini和o4-mini-high还是不可或缺的模型选项。
很多网友留言分享了自己的使用心得,不少人和卡帕西的体验有点不同:
面对和自己不一样的心得分享,卡帕西直接回复表示,他会在选择模型时进行首先进行一次「二选一」,因为二选一往往更简单。
也就是说,先判断这件事是重要的(并且自己愿意等待),还是不重要的(并且自己只想快速了解)。这基本上就决定了卡帕西会选择用o3还是4o模型。

当然,评论区少不了那个老生常谈的话题:
但凡是个用户,面对ChatGPT上这些名字各异、特长各异的模型,都得头疼一会。
咱就是说,OpenAI到底为啥把模型名字取得这么奇怪啊?
而且用户一直吐槽,OpenAI一直不改。
这回有人十分戏谑地回答了这个问题。
一切的一切,都是因为OpenAI有“不顾用户死活”的资本——当PMF达成后,别的一切都无关紧要。

万幸现在有了卡帕西的这份指南,用户们在选择模型时能少吃些苦头了。
以及,就像一位开发者说的那样:

参考链接:
[1]https://x.com/karpathy/status/1929597620969951434
[2]https://x.com/andrepaulj/status/1929647337330430074
[3]https://x.com/onurtskrncom/status/1929673955377373560
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/18698.html