
给AI生成的作品打水印,让AIGC图像可溯源,已经成为行业共识。
问题是,传统水印方法通常把图像当成一个整体处理,全局嵌入、水印提取一锅端,存在不少“短板”:
比如,图像局部区域被篡改,就可能导致全局提取失败,也无法定位水印所在具体区域。
又比如,无法只保护某个区域,如人脸、LOGO等。
针对这个问题,现在,来自南洋理工大学和新加坡A*STAR前沿人工智能研究中心等机构的研究人员,提出了一种全新的局部鲁棒图像水印方法——MaskMark
该方法不仅在多个任务中全面超越Meta出品的SOTA模型WAM,而且训练成本只有它的1/15。


具体而言,MaskMark支持:
- 多水印嵌入
- 可精准定位篡改区域
- 灵活提取局部水印
- 自适应支持32/64/128比特
核心思路:让模型“看得见”水印在哪里
研究人员引入了一种掩码机制,训练时告诉模型“水印藏在这里”,教它学会精准地嵌入和提取。
他们给MaskMark设计了两个版本:
MaskMark-D(解码掩码)
- 水印全图嵌入,但能定位水印位置,支持局部提取。
- 即使部分图像被篡改,也能成功提取水印。
- 适合用于整体图像保护、版权声明和内容验证。
MaskMark-ED(编码+解码掩码)
- 水印只嵌入图像的特定区域(比如人脸或LOGO)。
- 对小范围攻击更鲁棒,提取效果更好。
- 适合局部敏感内容保护、隐私感知场景等。
其中核心技术流程,是训练和推理的双重优化
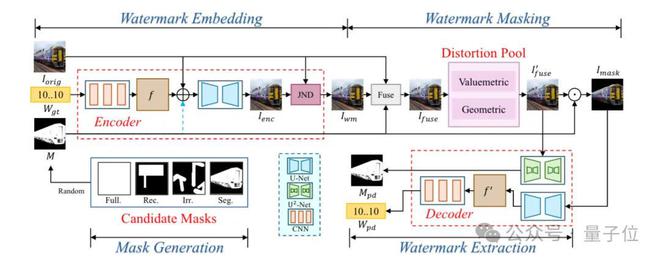
MaskMark 的端到端训练流程主要包括四个阶段:
- 掩码生成(Mask Generation):
- 从四种预定义类型(全掩码、矩形掩码、不规则掩码、分割掩码)中随机选择或生成一个掩码M。
- 水印嵌入(Watermark Embedding):
- 编码器将水印比特嵌入原始图像(对于 MaskMark-ED可选择性地嵌入掩码M来指导嵌入位置),生成水印图像。此过程利用轻量级CNN处理水印比特,并结合U-Net结构及JND模块优化视觉效果。
- 水印掩码操作(Watermark Masking):
- 使用掩码M融合和,生成,即仅在掩码区域保留水印。随后对施加随机失真得到,并再次用M裁剪出仅含水印信号的区域。
- 水印提取(Watermark Extraction):
- 解码器从中预测掩码,并从中提取水印比特。解码器包含专门用于掩码预测的 U2-Net 和用于水印提取的U-Net及CNN模块。
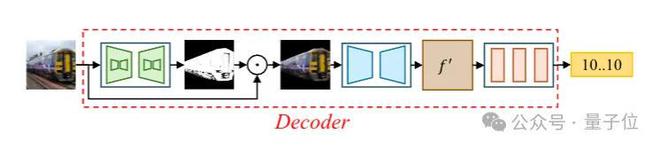
MaskMark推理时,解码器首先利用定位模块识别含水印区域,将非水印区域置零以减少干扰,然后从保留区域恢复水印,这对于小区域水印提取尤为重要。
在多项不同的任务上均表现出SOTA的性能
研究人员在多项不同任务上验证了MaskMark的性能。
首先,MaskMark能实现高提取精度
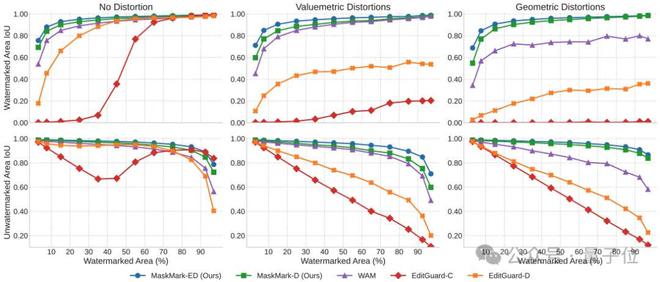
在全局水印任务中,即使在高视觉保真度(PSNR > 39.5, SSIM > 0.98)下,MaskMark-D和MaskMark-ED仍能保持近乎100%的比特准确率,尤其在各类值度量和几何失真攻击下表现优异,显着优于现有基线模型。
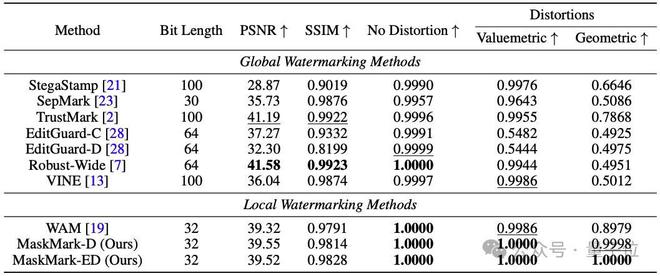
在局部水印任务中,实验表明,当水印信号分布在图像的不同大小区域时,MaskMark仍能保持近乎100%的提取准确率,显着优于其他全局方法,并超过当前最先进的局部水印模型WAM。尤其在小面积嵌入场景中,MaskMark-ED展现出更加出色的表现。
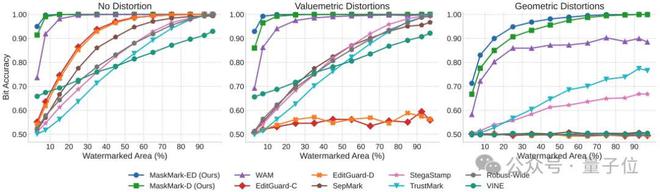
其次,MaskMark能实现精准水印定位
在不同水印区域比例和失真条件下,其定位性能(以IoU衡量)均优于EditGuard和WAM等方法。MaskMark-ED在小区域定位上更具优势。
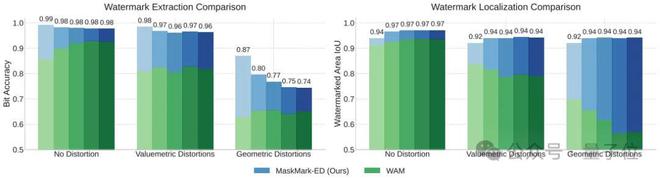
MaskMark还具备多水印嵌入能力
尽管并非为此专门训练,MaskMark-ED在单个图像中嵌入多达5个不同水印时,依然保持强大的提取和定位性能,优于WAM。
高效性和扩展性方面,训练效率上,MaskMark仅需在单个A6000 GPU上训练约20小时,计算效率(TFLOPs衡量)比WAM高出15倍。

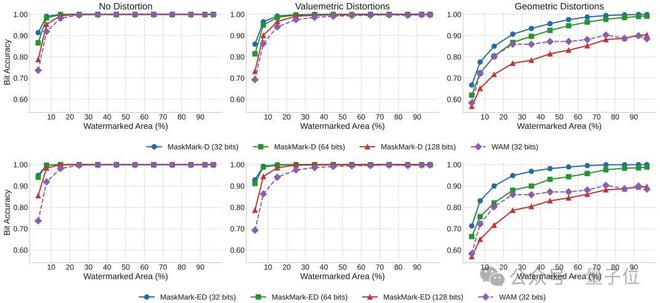
消息长度方面,MaskMark可轻松扩展至不同比特长度(如32、64、128位),并保持较高性能,而WAM则受限于32位。
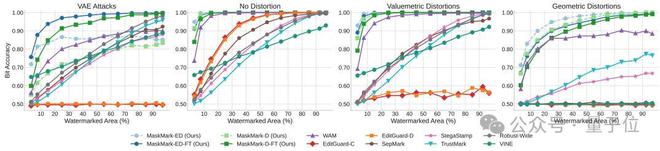
另外,MaskMark还支持快速微调*
通过简单调整失真层或进行少量微调(如针对VAE自适应攻击,仅需20k训练步数),MaskMark即可适应不同鲁棒性需求和新兴威胁。
论文链接:
https://arxiv.org/abs/2504.12739
代码链接:
https://github.com/hurunyi/maskmark
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/18403.html