
有点意思。
这不DeepSeek前脚刚刚上新了一篇关于推理时Scaling Law的论文嘛,引得大家纷纷联想是不是R2马上要来了
然鹅……奥特曼这边却发了一条“变卦”的消息:
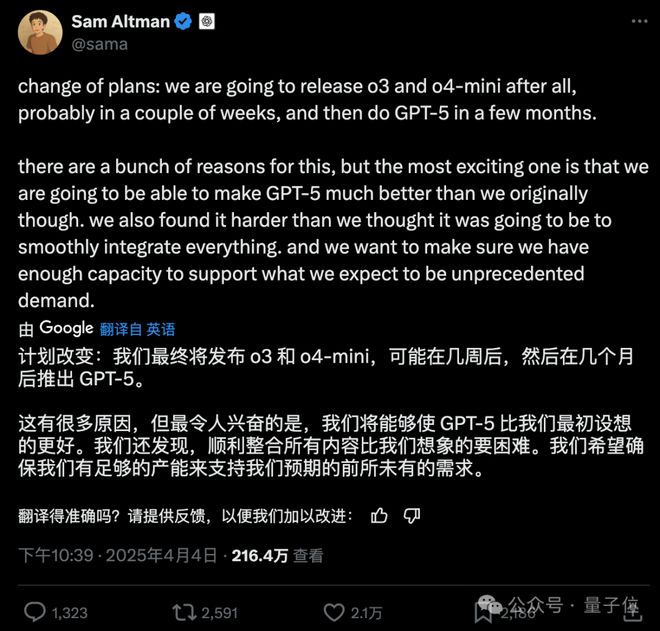

至于大家翘首以盼的GPT-5,奥特曼表示:
至于原因,奥特曼也做出了解释。
大概意思就是,顺利整合所有内容比他们想象的要困难得多,希望确保有足够的能力来支持预期的需求。

咱就是说啊,现在真的是DeepSeek这边一有点声响,OpenAI那边就得有点动作来紧跟一下了。
DeepSeek新论文
在这个小插曲之后呢,我们还是把目光聚焦在DeepSeek这篇新论文身上。
这篇论文的名字叫做Inference-Time Scaling for Generalist Reward Modeling,由DeepSeek和清华大学共同提出。

这篇研究核心的亮点,就是提出了一个叫做SPCT方法(Self-Principled Critique Tuning)的方法——
首次提出通过在线强化学习(RL)优化原则和批判生成,实现推理时扩展。
之所以要做这么一项研究,是因为之前大家用奖励模型(Reward Model, RM)在RL中为大语言模型生成奖励信号。
但现有的RM在通用领域却表现出受限的情况,尤其是在面对复杂、多样化任务的时候。
因此,就出现了两个关键挑战点。
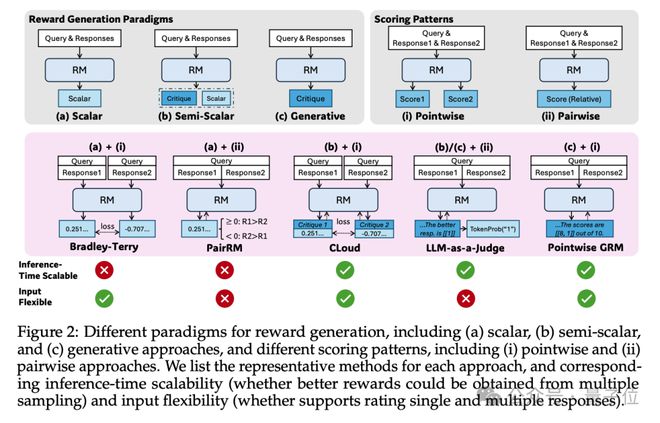
一个是通用RM需要灵活性(支持单响应、多响应评分)和准确性(跨领域高质量奖励)。
另一个则是现有RM(如标量RM、半标量RM)在推理时扩展性差,无法通过增加计算资源显着提升性能。
为了解决这个问题,DeepSeek和清华大学团队便提出了SPCT。
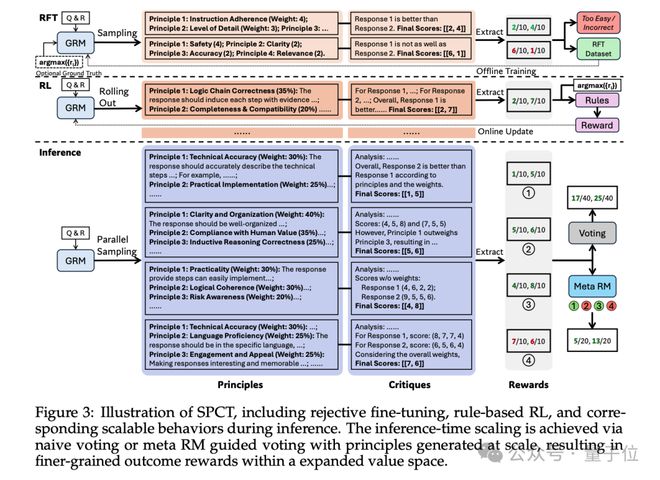
整体来看,这项研究主要包含三大核心技术点。
首先就是生成式奖励模型(GRM)。
它采用点式生成奖励模型(Pointwise GRM),通过生成文本形式的奖励(如critiques)而非单一标量值,支持灵活输入(单响应、多响应)和推理时扩展。
其中,C是生成的critique,fextract从中提取分数。
接下来,是关键的SPCT了。
主要是通过在线强化学习(RL)训练GRM,使其能动态生成高质量的原则(principles)和批判(critiques),从而提升奖励质量。
整体来看,SPCT是一个两阶段的过程,它们分别是:
- 拒绝式微调(Rejective Fine-Tuning)
- :冷启动阶段,通过采样和拒绝策略生成初始数据。
- 基于规则的在线RL
- :使用规则化奖励函数优化原则和批判的生成,鼓励模型区分最佳响应。
在此基础上,便是第三个技术点,即推理时扩展技术
先是通过多次采样生成多样化的原则和批判,投票聚合最终奖励,扩展奖励空间。
再训练一个辅助模型过滤低质量采样,进一步提升扩展效果。
基于上述的方法,团队也对结果做了一波测试。
在Reward Bench、PPE、RMB等基准上,DeepSeek-GRM-27B显着优于基线方法(如LLM-as-a-Judge、标量RM),且通过推理时扩展(32次采样)性能进一步提升(如Reward Bench准确率从86.0%提升至90.4%)。
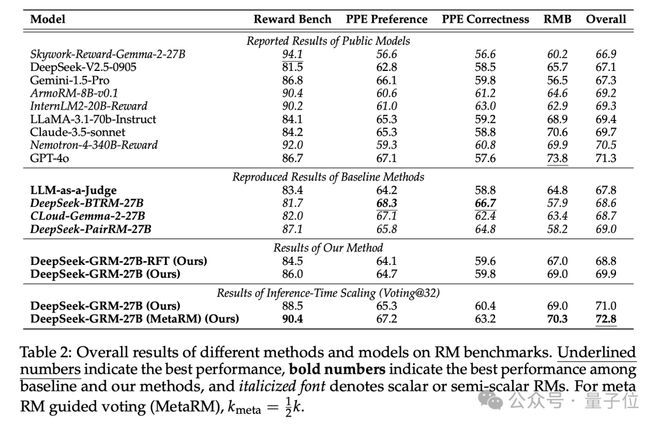
总而言之,这篇研究证明了推理时扩展在通用RM中的有效性,性能超越训练时扩展。
One More Thing
奥特曼发布“变卦”消息之外,还不忘给自己带一波货,称有两本他亲自参与的书即将发布:
- 一本是Keach Hagey写的关于奥特曼本人的书
- 一本是Ashlee Vance写的关于OpenAI的书
论文地址:https://arxiv.org/abs/2504.02495
[1]https://x.com/sama/status/1908167621624856998
[2]https://techcrunch.com/2025/04/04/openai-says-itll-release-o3-after-all-delays-gpt-5/
[3]https://x.com/sama/status/1908163013192069460
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/4168.html