
梦晨 发自 凹非寺
什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现?
新强化学习框架RAGEN,作者包括DeepSeek前员工Zihan Wang、斯坦福李飞飞团队等,可训练Agent在行动中深度思考。

论文一作Zihan Wang在DeepSeek期间参与了Deepseek-v2和Expert Specialized Fine-Tuning等工作,目前在美国西北大学读博。
他在介绍这项工作时上来就是一个灵魂提问:为什么你的强化学习训练总是崩溃?
而RAGEN正是探讨了使用多轮强化学习训练Agent时会出现哪些问题 ,以及如何解决这些问题。
通过大量实验,研究团队发现了训练深度推理型Agent的三大难点:
- Echo Trap(回声陷阱):多轮强化学习中,模型过度依赖局部收益的推理,导致行为单一化、探索能力衰退,从而影响长期收益。
- 数据质量:Agent生成的交互数据直接影响强化学习的效果。合理的数据应该具有多样性、适度的交互粒度和实时性。比如在单个任务上多试几次,每轮限制5-6个动作,并保持rollout的频繁更新。
- 缺乏推理动机:如果没有精心设计的奖励函数,Agent很难学会多轮任务中持续的推理能力。甚至会出现表面看起来能完成任务,实际上只是匹配了固定模式的假象。下一步的关键在于建立更细粒度、面向解释的奖励机制。
在交互式随机环境中训练推理Agent
RAGEN是一个模块化的Agent训练和评估系统,基于StarPO(State-Thinking-Actions-Reward Policy Optimization)框架,通过多轮强化学习来优化轨迹级别的交互过程,由两个关键部分组成:
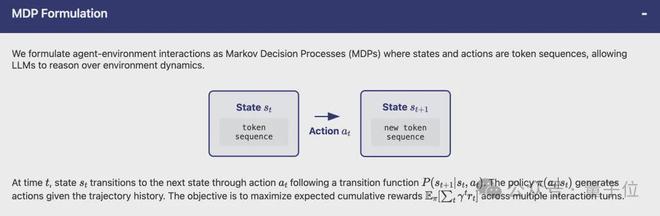
MDP Formulation
将Agent与环境的交互表述为马尔可夫决策过程(MDP),其中状态和动作是token序列,从而允许在环境动态上推理。
StarPO:通过轨迹级优化强化推理
StarPO是一个通用的强化学习框架,用于优化Agent的整个多轮交互轨迹,在两个阶段之间交替进行,支持在线和离线学习。
Rollout阶段:
给定初始状态,该模型会生成多条轨迹。在每一步中,模型都会接收轨迹历史记录并生成推理引导的动作。
…reasoning process…think>actionans>
环境接收动作并返回反馈(奖励和下一个状态)。

Update阶段:多回合轨迹优化
生成轨迹后,训练优化预期奖励。StarPO并非采用逐步优化的方式,而是使用重要性采样来优化整个轨迹。这种方法能够在保持计算效率的同时实现长远推理。
StarPO支持PPO、GRPO等多种优化策略。


除提出算法外,RAGEN论文中还重点介绍了通过研究推理稳定性和强化学习动态得出的6点主要发现。
6点主要发现
发现1:多轮训练引入了新的不稳定模式
像PPO和GRPO这样的单轮强化学习方法的adaptations在Agent任务中有效,但经常会崩溃。PPO中的“批评者”或许可以**延缓不稳定性,但无法阻止推理能力的下降,这凸显了在Agent任务中对专门的稳定性进行改进的必要性。
发现2:Agent强化学习中的模型崩溃体现为训练过程中的“回声陷阱”
早期智能体会以多样化的符号推理做出反应,但训练后会陷入确定性、重复性的模板。模型会收敛到固定的措辞,这表明强化学习可能会强化表面模式而非一般推理,并形成阻碍长期泛化的“回声陷阱”。
发现3:崩溃遵循类似的动态,可以通过指标预测
奖励的标准差和熵通常会在性能下降之前发生波动,而梯度范数的峰值通常标志着不可逆崩溃的临界点。这些指标提供了早期指标,并激发了对稳定策略的需求。
发现4:基于不确定性的过滤提高了训练的稳定性和效率
基于奖励方差过滤训练数据可以有效对抗“回声陷阱”。仅保留高度不确定的训练实例可以延迟或防止跨任务崩溃,并提高数据效率。
发现5:任务多样性、行动预算和推出频率影响数据质量
多样化的任务实例能够实现更好的策略对比和跨环境泛化。合适的行动预算能够提供充足的规划空间,并避免过长序列引入的噪声。Up-to-date rollouts能够确保优化目标与当前策略行为保持一致。
发现6:如果没有精心的奖励设计,推理行为就无法产生
虽然符号推理在弱监督下的单轮任务中自然出现,但在多轮环境中,如果没有明确鼓励可解释的中间推理步骤的奖励设计,它就无法持续存在。
团队观察到,即使有结构化的提示,如果奖励信号仅关注最终结果,推理能力也会在训练过程中逐渐衰退。这表明如果没有细致的奖励塑造,智能体可能会倾向于走捷径,完全绕过推理。
One More Thing
同团队还有另一个项目VAGEN,使用多轮强化学习训练多模态Agent。
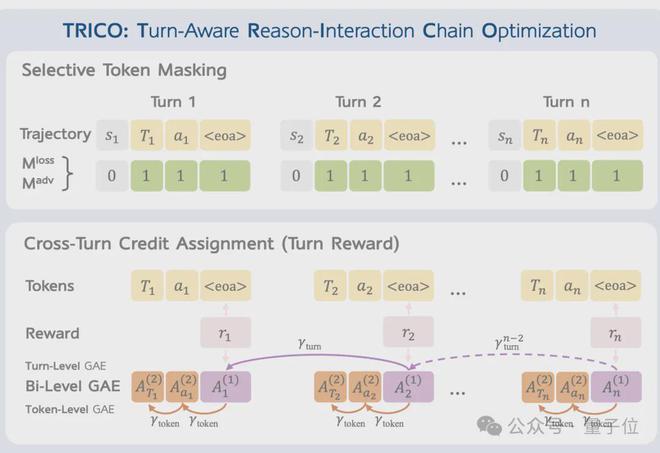
VAGEN 引入了回合感知推理交互链优化 (TRICO) 算法,通过两项关键创新扩展了传统的RICO方法:选择性token屏蔽,跨轮credit分配。
与传统的Agent强化学习相比,VAGEN不会平等对待轨迹中的所有token,而是重点优化最关键的决策token并在交互过程中创建更细致的奖励结构,更适合多模态Agent
RAGEN、VAGEN代码均已开源,感兴趣的团队可以跑起来了。
论文:
https://github.com/RAGEN-AI/RAGEN/blob/main/RAGEN.pdf
代码
https://github.com/RAGEN-AI/RAGEN
https://github.com/RAGEN-AI/VAGEN
[1]https://ragen-ai.github.io
[2]https://x.com/wzihanw/status/1915052871474712858
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/8271.html