
不得了。
现在的国产AI应用,一口气看好几分钟的视频,都可以直接做推理和解析了!
瞧~只需“喂”上一段柯南片段,AI就摇身一变成“名侦探”做剖析:


视频地址:https://mp.weixin.qq.com/s/JIsEmAk1T16YcYpXAOrJHw
它会对整个视频的内容先做一个总结,再按照秒级,对视频片段做内容上的推演。
如果再给这个AI“喂”上一段足球游戏,它又会秒变成一位资深解说员:
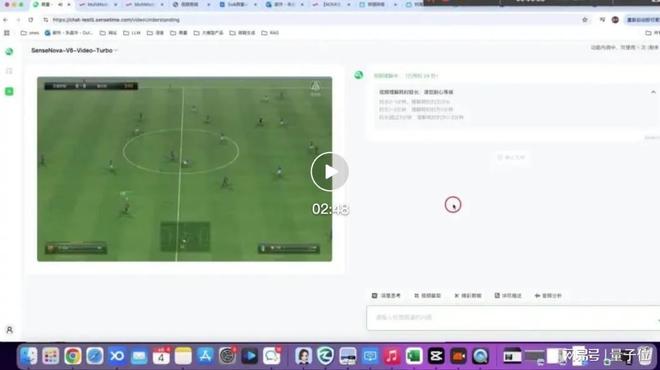
视频地址:https://mp.weixin.qq.com/s/JIsEmAk1T16YcYpXAOrJHw
这一次,在视频总结和视频要点之后,我们继续提出要求:
它就会立即执行深度思考,自动剪辑出一段8秒的高光片段,并附上建议搭配的音乐或音效:
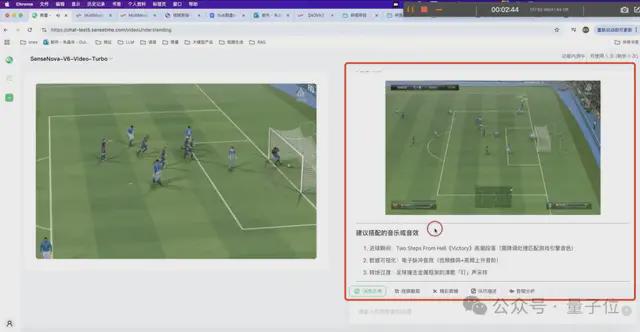
这便是商汤最新升级的日日新SenseNova V6解锁的新能力——
原生多模态通用大模型,采用6000亿参数MoE架构,实现文本、图像和视频的原生融合。

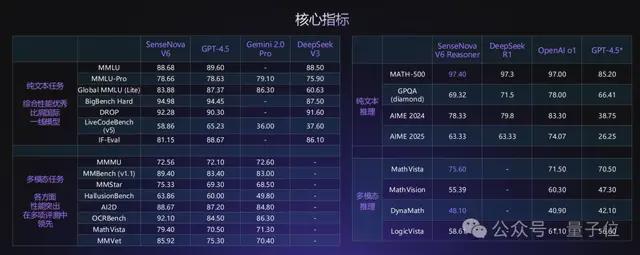
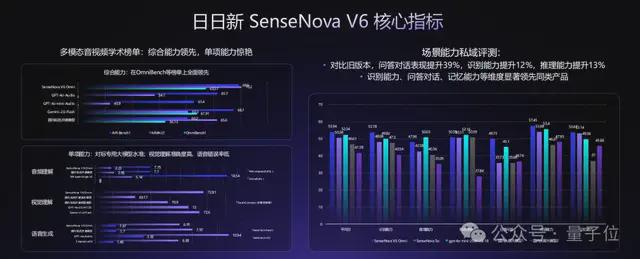
从性能评测来看,SenseNova V6已经在纯文本任务和多模态任务中,多项指标均已超越GPT-4.5、Gemini 2.0 Pro,并全面超越DeepSeek V3:
在强推理能力上,日日新V6/V6 Reasoner的多模态和语言深度推理任务上同时超过了OpenAI的o1和Gemini 2.0 flash-thinking的水平。
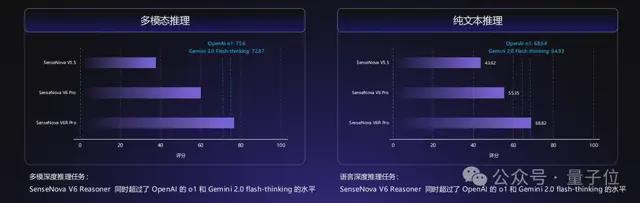
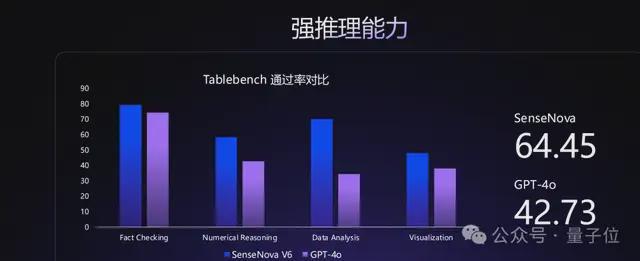
同时在小版本的模型上,SenseNova V6的各项成绩也超越GPT-4o:
纵观整体,可以将商汤此次发布新模型的特点总结为三个关键词——
强推理、强交互和长记忆。
那么具体效果如何,我们继续往下看。
边看边听边理解的AI
这次我们的实测主要聚焦在实时音视频交互的能力上。
我们直接用全新版本的商量APP(内测版)来做一波测试。
测试的视频,便是最近大火的韩剧《苦尽柑来遇见你》中女主妈妈让婆婆陪她一起去拍遗像的片段:

视频地址:https://mp.weixin.qq.com/s/JIsEmAk1T16YcYpXAOrJHw
AI在看了整整五分钟视频之后,对于我们的三连问都给出了精准的答案:
不仅如此啊,从AI的回复中,我们也可以听出情绪上的变化,对于这样令无数人催泪的桥段,它作答的情绪也是略带sad。
再来一个比较有意思的——看图猜城市:

AI的回答如下:
视频地址:https://mp.weixin.qq.com/s/JIsEmAk1T16YcYpXAOrJHw
在一番深度思考之后,AI是精准猜到了长沙这个城市。
类似的,我们再来做一个猜成语的游戏,题目长这样:

这一次,AI更是没有过多的“废话”,直击要害地给出了答案——缘木求鱼。

视频地址:https://mp.weixin.qq.com/s/JIsEmAk1T16YcYpXAOrJHw
不光是有趣,在面对日常生活中的问题,商汤SenseNova V6更是能够体现它有用的价值。
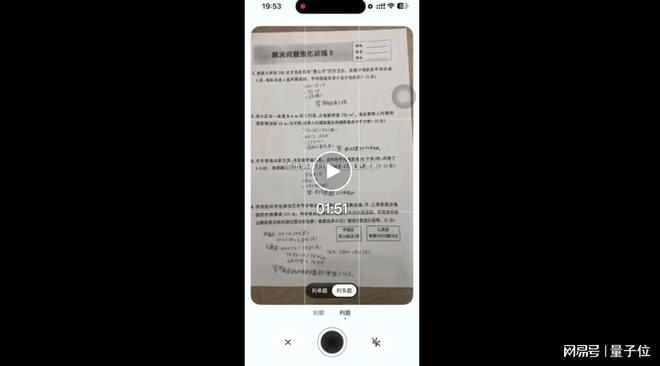
比如给小朋友辅导数学题,现在真的就是一拍一问就可以的事情了。
要知道,普通大模型只会提供千篇一律的标准答案,无法基于不同的解题思路提供指导。
但日日新V6不但能识别手写体,还能够提供针对错误点的一对一引导式讲解,并给与高效辅导:
视频地址:https://mp.weixin.qq.com/s/JIsEmAk1T16YcYpXAOrJHw
从多种维度的实测来看,SenseNova V6是具备了高度拟人化的感知、表达和情感理解能力,可针对不同的对话内容和场景需求,即时灵活地切换语气、情感与音调。
同时,它还拥有较强的实时交互、视觉识别、记忆思考、持续对话和复杂推理等能力。
除此之外,商汤的SenseNova V6,还上身了今年持续爆火的具身智能,可以说是用它多模态的能力,给机器人装上大脑、眼睛、耳朵和嘴巴:

怎么做到的?
看完各种实测,我们再来聊聊SenseNova V6背后的原理。
为了更好地理解,量子位与商汤科技联合创始人、执行董事及人工智能基础设施和大模型首席科学家林达华请教了一番。
首先,就是商汤自研的原生多模态融合训练技术。
这是一种能够将多种模态信息(如文本、图像、视频、音频等)在模型架构和训练过程中进行深度融合的AI模型架构。
与传统的将语言模型和多模态模型分立的方式不同,它通过桥接技术(如补充训练数据和模态关联机制)实现模态间的协同,避免传统方法中“跷跷板效应”(即增强某一模态能力导致另一模态能力下降)。
这种设计能更自然处理复杂场景(如漫画理解、视频分析),捕捉跨模态的细节关联(如图像中的隐含信息)。
在今年1月份的权威评测榜单SuperCLUE(语言模型综合榜单)和OpenCompass(多模态综合榜单)上均位列国内第一,这也充分证明了该技术的强大潜力。
其次,是多模态长思维链合成技术。
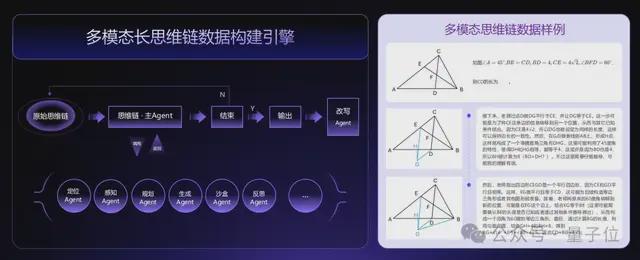
面对复杂推理任务,传统AI模型容易因信息过长而丢失关键逻辑;商汤的这一技术可以通过多智能体协作,实现超长思维链的生成与验证(目前储备超1000万条思维链数据)。
具体而言,它可以合成并理解64K tokens(约5万字)的多模态长思维链,使模型具备长时间、多步骤的深度思考能力,适用于数学推导、科学分析、长文档理解等场景。
林达华举例说明,模型在回答问题时能逐步关联图像细节(如漫画中的海鸥表情),最终生成富有创造力的输出。
除此之外,还有多模态混合增强学习。
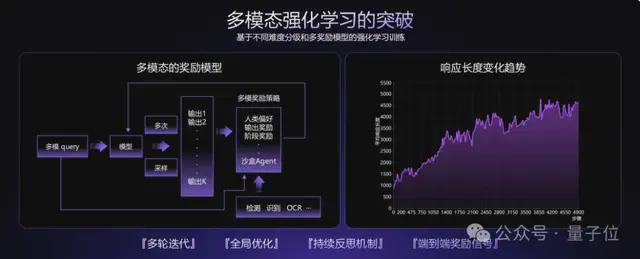
这一技术的提出主要是为了平衡模型的逻辑推理能力和情感表达能力。
它同时采用基于人类偏好的RLHF(强化学习人类反馈)和基于确定性答案的RFT(强化学习事实训练),使模型既符合人类喜好,又保证事实准确性。
并且通过智能权重调整,确保模型在提升推理能力的同时,不会变得机械生硬,仍能自然表达情感。
最后,便是长视频统一表征和动态压缩。
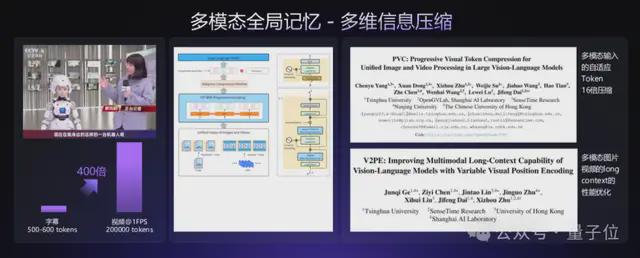
长视频理解一直是AI的难题,商汤的统一时序表征技术实现了跨模态信息的高效对齐与压缩。
它可以将画面(视觉)、语音(听觉)、字幕(文本)、时间逻辑统一编码,形成连贯的时序表征。
在采用细粒度级联压缩+内容敏感过滤之后,10分钟的长视频可压缩至16K tokens(仅为原始数据的极小部分),同时保留核心语义,大幅提升处理效率。
以上四大技术,便是商汤SenseNova V6背后的杀手锏了。
不仅要日日新,还要天天用
遥想百模大战之初,商汤CEO徐立博士解释过为何商汤大模型会取名为“日日新”:
其本意是如果一天能够自新,就该天天自新,持续不断地革新;这也意味着商汤的大模型版本会持续更新,能力“日新月异”。
现在回头来看,从SenseNova V1到现在的V6,商汤大模型发展速度确实是做到这一点:平均3-4个月便会有一次的迭代。
而从今天的发布会来看,不论是从技术的解读,亦或是案例、demo的分享,无不在剑指易用性。
大到城市管理、物业运营、电网巡检,小到数学解题、游戏解说、绘本故事……
一言蔽之,商汤在透露的核心观点便是:

对此,徐立博士也对量子位做了更进一步的阐述:
除此之外,借着此次SenseNova V6“上身”具身智能,还延伸出了一个有趣的话题——
前不久某知名创投圈大佬一句“批量退出具身智能”引发了不小热议。
对此,商汤科技联合创始人杨帆认为:
银河通用合伙人、大模型负责人张直政表示:
除此之外,上海交通大学副教授闫维新对这个问题的看法是:

总而言之,商汤作为国内大模型代表性玩家,它今天所强调的“AI之道”,一来是符合当今大模型发展“应用为王”的趋势,更是反应出了AI发展的根本价值取向——
技术必须服务于人的真实需求,融入日常生活,解决实际问题。
那么今天,你用AI了吗?赶快去试试SenseNova V6吧~
chat.sensetime.com
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/4343.html