
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!
清华和上海AI Lab周伯文团队用这样的方法,对模型进行了强化——
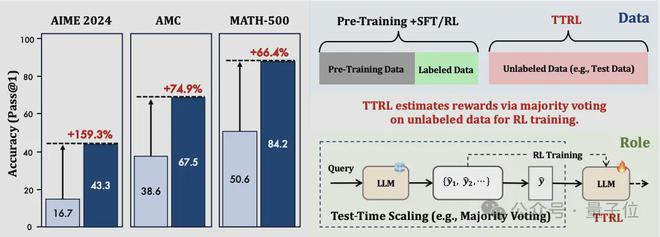
结果模型在多个数据集上的成绩均大幅提升,尤其是Qwen-2.5-Math-7B,它做AIME 2024竞赛题的成绩直接提高了159%。

实验过程中,强化学习的数据均由被训练的模型自身生成。
作者还发现,训练后的模型性能,准确性已经超过了用于训练它的伪标签(测试时强化学习过程中产生)。
DeepMind工程师评价,这种测试时强化学习的方式将改变LLM的格局:
模型自己生成强化学习数据
作者提出的测试时强化学习(TTRL)过程是测试时扩展和测试时训练的结合,具体可以分为“生成、投票、强化”三个大步骤。
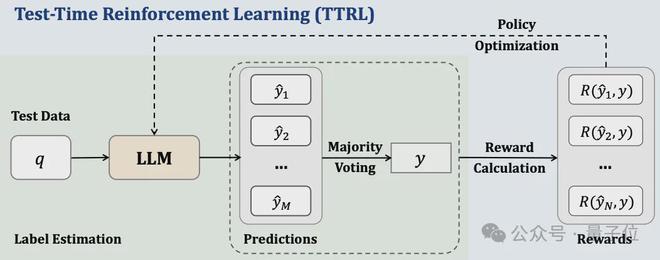
第一步生成的目的,是让模型针对每个输入的prompt,生成尽可能多样化的候选答案,该过程通过测试时推理来实现。
其思路是在推理阶段增加计算资源以获得更好的性能,具体到TTRL采用的是增加采样数量的方式,即对每个prompt,让模型采样生成N个不同的答案,而不是只生成一个确定性最高的输出。
作者的实验中,当在AIME 2024数据集上应用TTRL训练Qwen2.5-Math-7B模型时,每个prompt采样64次(N=64),温度系数设为1.0,以鼓励模型生成多样化的答案。
投票过程从上一步生成的N个候选答案出发,通过多数投票的方式来估计正确答案,并将其作为伪标签。
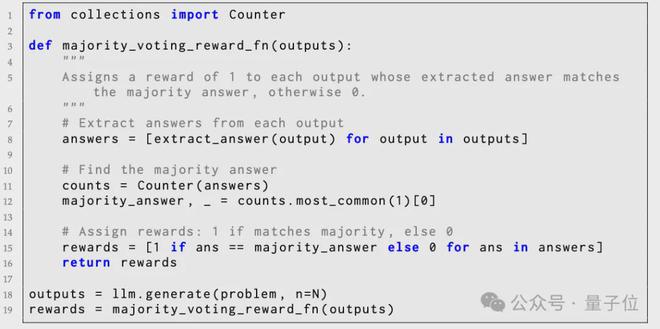
TTRL在实际应用投票机制时还引入了一个参数 Maj@N,表示多数投票的估计准确率。
它衡量的是伪标签与真实标签的一致性。通过控制Maj@N,可以权衡伪标签的质量和数量。
最后一步利用强化学习,基于上一步估计出的伪标签,来优化语言模型的策略,使其倾向于给出正确答案。
TTRL采用GRPO算法,还加入了重要性采样和蒙特卡洛估计等技术,以提高训练效率和稳定性。
模型数学能力大幅提升
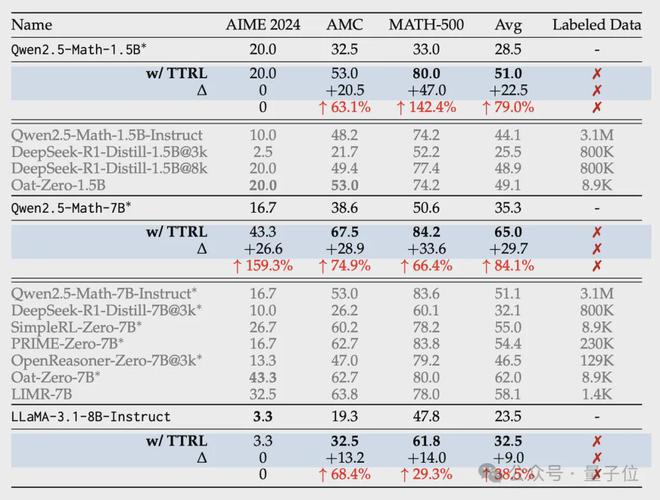
为了评估TTRL的效果,作者在AIME 2024、AMC和MATH-500三个数据集上对调整前后的三款模型进行了测试。
- 在AIME 2024数据集上,对于Qwen2.5-Math-7B基础模型,TTRL将其准确率从16.7%提高到43.3%,提升幅度高达159.3%,超越了所有在大规模标注数据上训练的模型。
- 在AMC数据集上,Qwen2.5-Math-7B、Qwen2.5-Math-1.5B和LLaMA模型的准确率分别获得了74.9%、63.1%和68.4%的大幅提高。
- MATH-500数据集上的表现更为突出,Qwen2.5-Math-7B和Qwen2.5-Math-1.5B分别实现了66.4%和142.4%的惊人提升,LLaMA模型的准确率也提高了29.3%。
平均而言,TTRL使Qwen2.5-Math-7B模型在三个数据集上的性能提高了84.1%。
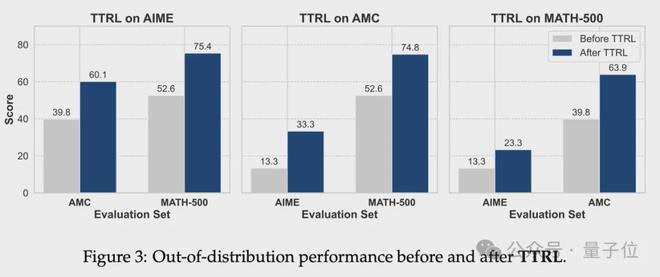
进一步的泛化性实验表明,在一个数据集上应用TTRL后,性能的提高可以自然迁移到其他数据集,甚至是从未参与训练的任务。
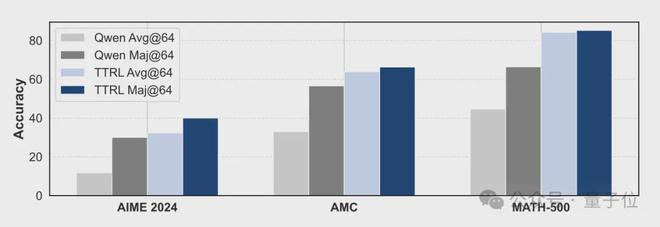
为了分析TTRL方法有效的原因,作者比较了TTRL训练前后模型的多数投票性能。
结果,应用TTRL后,模型的多数投票准确率(Maj@64)显着高于原始的Qwen模型,说明通过多数投票得到的伪标签质量优于单个模型输出。
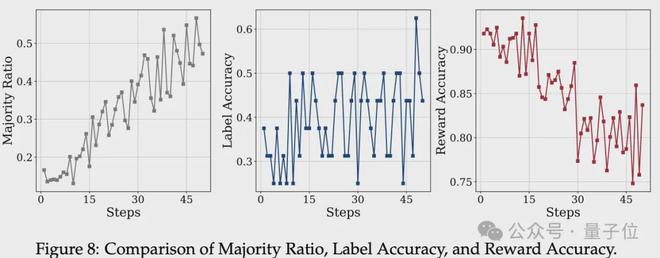
并且强化学习具备纠错能力。即使伪标签并非完全准确,强化学习也可以通过奖惩机制引导模型朝着正确方向优化。
从AIME 2024上标签准确率和奖励准确率的变化曲线中可以看到,即使在标签准确率较低的阶段,奖励准确率也能维持在90%以上。
作者简介
这项研究的领导者是清华大学C3I课题组博士生张开颜和上海AI实验室青年研究员崔淦渠。
张开颜的导师是上海人工智能实验室主任、首席科学家周伯文教授;崔淦渠则毕业于清华NLP实验室,读博期间导师是刘知远副教授。
本文共同一作是张开颜和同样来自清华的Yuxin Zuo,周伯文和C3I课题组博士后丁宁是本文的通讯作者。

论文地址:
https://arxiv.org/abs/2504.16084
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/7982.html