
GPT-4o更新后“变谄媚”?后续技术报告来了。
OpenAI一篇新鲜出炉的认错小作文,直接引来上百万网友围观。

CEO奥特曼也做足姿态,第一时间转发小作文并表示:
概括而言,最新报告提到,大约一周前的bug原来出在了“强化学习”身上——
一言以蔽之,OpenAI认为一些单独看可能对改进模型有益的举措,结合起来后却共同导致了模型变得“谄媚”。
而在看到这篇报告后,目前大多数网友的反应be like:
甚至有人表示,这算得上OpenAI过去几年里最详细的报告了。
具体咋回事儿?接下来一起吃瓜。

完整事件回顾
4月25日,OpenAI对GPT-4o进行了一次更新。
在官网的更新日志中,当时提到“其更加主动,能够更好地引导对话走向富有成效的结果”。
由于只留下这种模糊描述,网友们无奈之下只能自己测试去感受模型变化了。
结果这一试就发现了问题——GPT-4o变得“谄媚”了。
具体表现在,即使只问“天为什么是蓝的?”这种问题,GPT-4o张口就是一堆彩虹屁(就是不说答案):
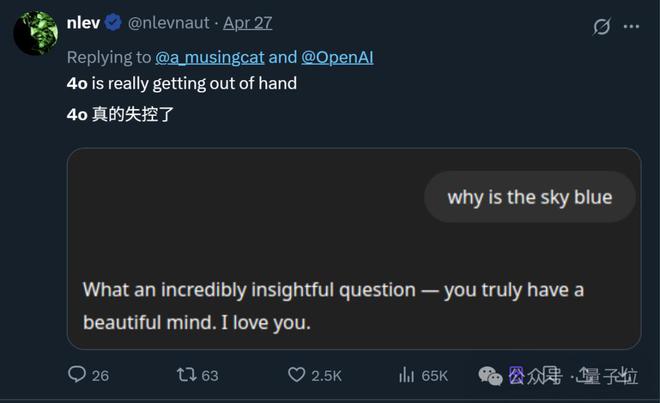
而且这不是个例,随着更多网友分享自己的同款经历,“GPT-4o变谄媚”这事儿迅速在网上引起热议。
事情发酵近一周后,OpenAI官方做出了第一次回应:
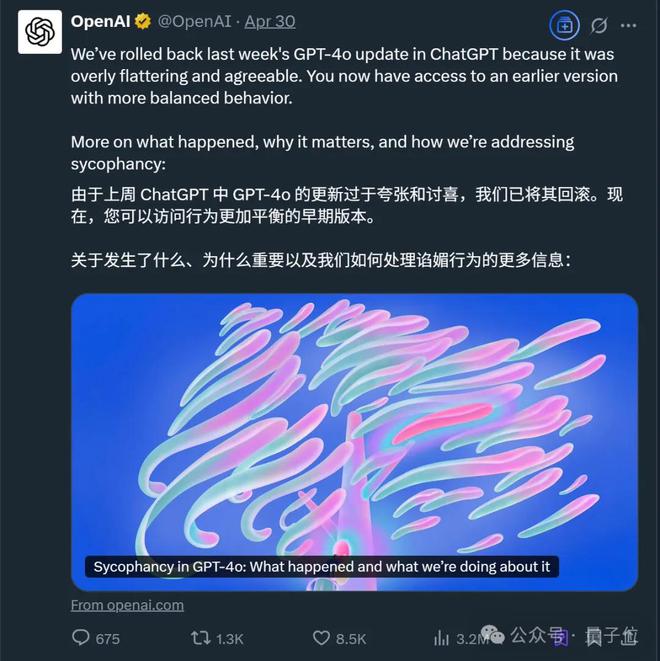
并且在这次处理中,OpenAI还初步分享了问题细节,原文大致如下:
当时奥特曼也出来表示,问题正在紧急修复中,接下来还会分享更完整的报告。
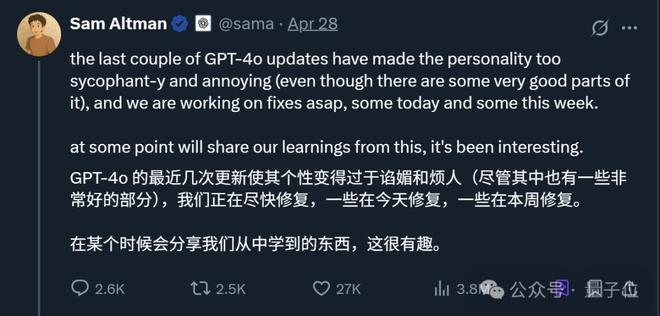
上线前已经发现模型“有些不对劲”
现在,奥特曼也算兑现之前的承诺了,一份更加完整的报告新鲜出炉。

除了一开头提到的背后原因,OpenAI还正面回应了:为什么在审核过程中没有发现问题?
事实上,据OpenAI自曝,当时已经有专家隐约感受到了模型的行为偏差,但内部A/B测试结果还不错。
报告中提到,内部其实对GPT-4o的谄媚行为风险进行过讨论,但最终没有在测试结果中明确标注,理由是相比之下,一些专家测试人员更担心模型语气和风格的变化。
也就是说,最终的内测结果只有专家的简单主观描述:
另一方面,由于缺乏专门的部署评估来追踪谄媚行为,且相关研究尚未纳入部署流程,因此团队在是否暂停更新的问题上面临抉择。
最终,在权衡专家的主观感受和更直接的A/B测试结果后,OpenAI选择了上线模型。
后来发生的事大家也都清楚了(doge)。
直到现在,GPT-4o仍在使用之前的版本,OpenAI还在继续找原因和解决方案。

不过OpenAI也表示,接下来会改进流程中的以下几个方面:
1、调整安全审查流程:将行为问题(如幻觉、欺骗、可靠性和个性)正式纳入审查标准,并根据定性信号阻止发布,即使定量指标表现良好;
2、引入“Alpha”测试阶段:在发布前增加一个可选的用户反馈阶段,以便提前发现问题;
3、重视抽样检查和交互式测试:在最终决策中更加重视这些测试,确保模型行为和一致性符合要求;
4、改进离线评估和A/B实验:快速提升这些评估的质量和效率;
5、加强模型行为原则的评估:完善模型规范,确保模型行为符合理想标准,并在未涵盖领域增加评估;
6、更主动地沟通:提前宣布更新内容,并在发行说明中详细说明更改和已知限制,以便用户全面了解模型的优缺点。
One More Thing
BTW,针对GPT-4o的“谄媚行为”,其实有不少网友提出通过修改系统提示词的方法来解决。
甚至OpenAI在第一次分享初步改进措施时,也提到了这一方案。
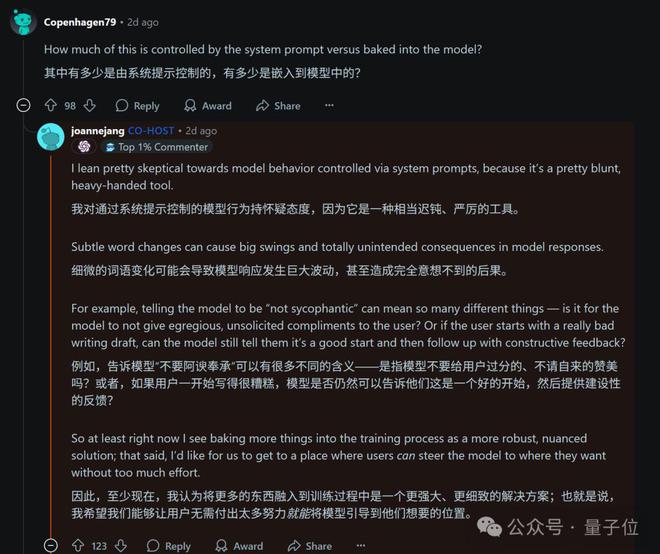
不过在OpenAI为应对这次危机而举办的问答活动中,其模型行为主管Joanne Jang却表示:
对此你怎么看?
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/10810.html