
超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!
华中科技大学、北京邮电大学等多所高校研究团队共同推出的Perception-R1(PR1),在视觉推理中最基础的感知层面,探究rule-based RL能给模型感知pattern带来的增益。
PR1重点关注当下主流的纯视觉(计数,通用目标检测)以及视觉语言(grounding,OCR)任务,实验结果展现出在模型感知策略上的巨大潜力。


目前论文和代码模型均已开源,作者希望其工作能给社区提供一个强大的baseline来支持后续研究。
眼见为实:为何AI视觉感知需要一场革命
随着OpenAI o3的出现,大模型竞赛也正式进入以“视觉推理”为代表的下半场,从GPT-4V到如今的o3,两年时间,人工智能正在迅速改变人与世界互动的方式,而这场革命在很大程度上依赖于AI理解视觉信息的能力。
从自动驾驶汽车在复杂的街道上导航,到医疗AI从扫描图像中诊断疾病,甚至是整理照片库的应用程序,视觉感知都是基础。
多模态大语言模型(MLLM),如OpenAI的GPT-4o、Google的Gemini,以及开源的Qwen-VL和LLaVA,代表了巨大的进步。这些模型将语言模型(LLM)的语言理解能力与处理图像的能力相结合,使我们能够与AI“交谈”关于图片的内容。询问它们图片中有什么,它们通常能告诉你。
然而,在识别物体和真正以细致入微的理解和逻辑感知视觉世界之间存在微妙的差异。虽然MLLM在一般的视觉问答方面越来越出色,但它们在需要精确物体定位、准确计数多个物体、在复杂布局中完美阅读文本或执行复杂视觉推理的任务上常常表现不佳。这就像知道图片中有一只猫和能够精确指出它的耳朵、计算它的胡须或理解它与其他物体的互动之间的区别。
强化学习的崛起与Perception-R1的诞生
强化学习(Reinforcement Learning, RL)引发了语言模型的范式转变。像RLHF(来自人类反馈的强化学习)和基于规则的RL等技术,在DeepSeek-R1中被用来解锁 emergent reasoning 能力,推动LLM向更强的推理能力发展。
这引出了一个问题:强化学习能否为MLLM的视觉感知能力带来类似的革命?
早期的尝试显示出希望,但并非通用的成功。简单地将语言领域的RL技术应用于视觉任务并不总能产生预期的收益。这暗示视觉感知可能遵循与纯语言不同的规则。
Perception-R1 应运而生。由华科,北邮以及JHU等高校的研究人员联合开发的开创性框架,如论文中所描述的那样这种方法回归到基本原理,探索如何有效地将基于规则的强化学习定制到MLLM视觉感知的独特挑战中。这不仅仅是让MLLM看起来更好,而是通过学习最佳的“感知策略”(Perception Policy)来教导它们更智能地看。
Perception-R1框架:工作原理
Perception-R1 不是从头开始构建一个新的MLLM,而是一个后训练框架,旨在通过基于规则的强化学习显着增强现有 capable MLLM(如Qwen2-VLInstruct-2B)的视觉感知能力。
什么是“感知策略”?
“感知策略”可以视为MLLM处理视觉任务的内部策略,具体包括以下步骤:
- 从图像中提取和理解相关的视觉细节。
- 基于这种视觉理解执行逻辑操作(例如,比较位置、识别实例、识别文本)
- 以正确的格式生成所需的输出(例如,边界框坐标、计数、转录文本)
Perception-R1 使用一种名为Group Relative Policy Optimization(GRPO)的强化学习技术来优化这一策略。GRPO 曾在DeepSeek-R1中取得成功,其工作原理如下(简版):
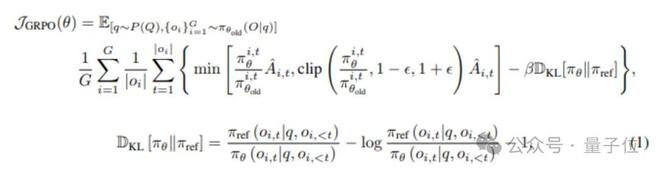
GRPO原理公式:
- Rollout(多次尝试):要求模型多次生成输出(例如,8次)。由于生成中的随机性(由温度参数控制),每次输出可能略有不同。
- 奖励建模:根据明确的评分标准(奖励函数)评估每次尝试。例如,对于边界框任务,使用Intersection over Union(IoU)衡量模型输出与正确答案的重叠程度。
- 相对比较:GRPO 通过比较多次尝试的奖励分数,计算平均值。优于平均水平的尝试获得正“优势”,低于平均水平的获得负“优势”。
- 策略更新:利用这些相对优势更新模型的策略,增加生成高奖励输出的概率,减少低奖励输出的概率。
- 重复优化:在大量示例上重复此过程,逐步优化感知策略。
具体框架如下:
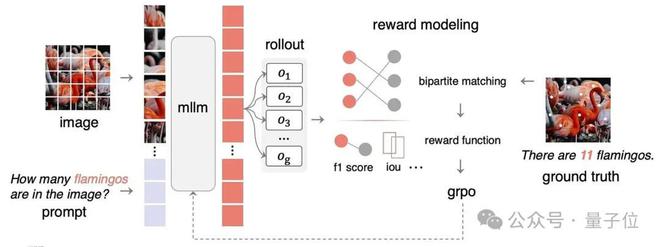
△Perception-R1 架构示意图
做好视觉任务的关键:奖励工程(Reward Modeling)
在强化学习中,奖励函数至关重要,它是指导学习过程的核心信号。视觉感知任务通常具有直接、可量化的 ground truth,Perception-R1 利用这一点设计了基于规则的奖励函数,总奖励由两部分组成:
- 格式奖励:检查输出是否符合预期结构。例如,边界框任务要求输出
- 为格式,正确则得+1分,错误则扣-1分。
- 答案奖励:衡量感知的正确性,使用任务特定的指标:
- 视觉定位(RefCOCO):预测边界框与 ground truth 的 IoU。
- 视觉计数(PixMo-Count):将任务重新定义为点检测后计数,奖励基于预测点与ground truth点的欧几里得距离。
- 光学字符识别(OCR – PageOCR):预测文本与 ground truth 的编辑距离(Levenshtein distance)
多主体奖励匹配的挑战与解决方案
对于涉及多个实例的任务(如物体检测和计数),如何匹配预测结果与 ground truth 是一个难题。Perception-R1 采用二分图匹配解决:
- 将预测结果和 ground truth 视为两组点。
- 计算每对之间的潜在奖励(例如,IoU)
- 使用匈牙利算法找到总奖励最大的最优匹配。
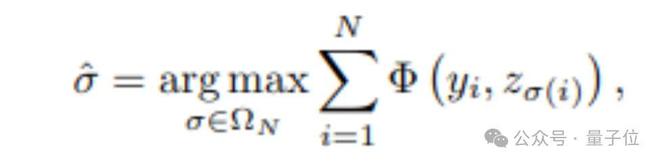
这确保了奖励计算基于最佳对应关系,为多物体感知任务提供了更准确的学习信号。最终总奖励为:
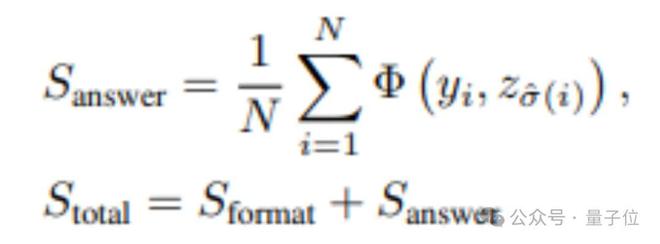
实验结果:Perception-R1的突破性表现
Perception-R1 的实际表现如何?研究人员在一套标准视觉感知基准上对其进行了评估,并将其与强大的基准 MLLM(如原始 Qwen2-VL-2B-Instruct)进行了比较,甚至与只为特定任务设计的专门 “专家 “模型进行了比较。
visual grounding任务(RefCOCO/+/g)
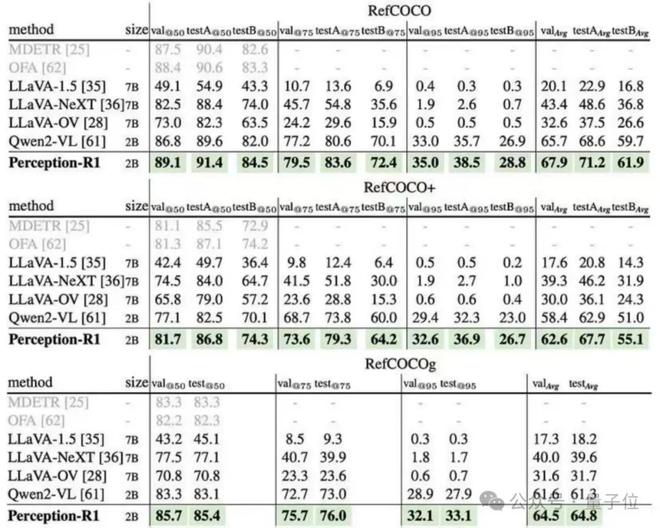
△visual grounding评测
OCR任务(PageOCR)
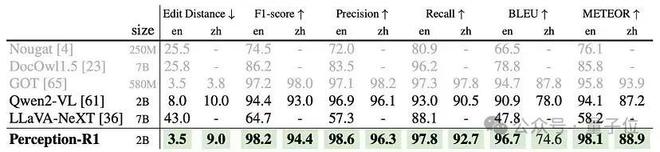
△PageOCR评测
视觉计数任务(Pixmo-Count)以及目标检测任务(COCO2017)

△视觉计数和目标检测评测
通用图像理解(general image understanding)

△image understanding and reasoning 评测
重要消融实验
Perception-R1也进行了全面的消融实验来探究现阶段rule-based RL对perception policy learning的有效性会受到哪些方面影响,研究人员详细评测了reward matching,是否使用显式的thinking以及SFT与RL优劣的问题都进行了深刻的探讨,接着Perception-R1也展示其良好的可扩展特性,为后续大规模scale up提供了实验验证。
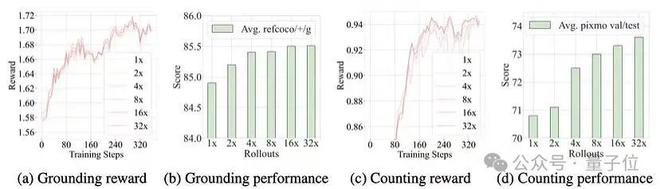
△Perception-R1的可扩展性实验
结论:迈向更加智能的AI视觉感知
Perception-R1 表明,当强化学习被精心适配到视觉任务的独特特性时,它可以成为教导大模型更准确、更逻辑地“看”的强大工具。通过优化感知策略,该框架推动了MLLM在物体检测、计数和OCR等任务上的能力边界。
尽管真正的视觉“顿悟”仍需探索,Perception-R1奠定了关键基础。它挑战了视觉任务必须依赖语言推理的假设,并强调了任务复杂性对RL效果的重要性。
随着模型规模扩大和更具挑战性的基准出现,Perception-R1的原则可能在构建下一代智能感知AI系统中发挥关键作用。
论文链接:https://arxiv.org/pdf/2504.07954
代码链接:https://github.com/linkangheng/PR1博客链接:https://medium.com/@jenray1986/perception-r1-reinventing-ai-vision-with-reinforcement-learning-253bf3e77657
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/10799.html