
OpenAI GPT-4o发布强大图片生成能力后,业界对大模型生图能力的探索向全模态方向倾斜,训练全模态模型成研发重点。
开源的MLLMs和扩散模型已经过大规模预训练,其从零开始训练统一任务,不如取长补短,将MLLMs的语言建模能力,与扩散模型的像素级图像建模能力,进行有机的结合。
基于这个思路,ModelScope团队提出可同时完成图像理解、生成和编辑的统一模型Nexus-Gen,在图像质量和编辑能力上达GPT-4o同等水平,并将成果全方位开源,望引发开发者讨论,促进All-to-All模型领域发展。


模型先进行图像生成,然后进行图像理解的可视化案例:

Nexus-Gen技术细节
总体框架
Nexus-Gen采用了与GPT-4o类似的 token → [transformer] → [diffusion] → pixels 技术路线,融合了SOTA MLLMs的强大文本预测能力和Diffusion模型的强大图像渲染能力,其总体架构如图所示。
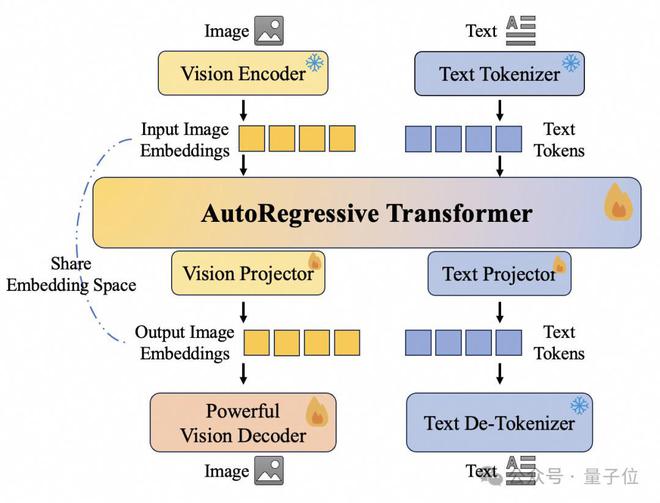
作为一个All-to-All模型,Nexus-Gen的输入和输出都支持图像和文本模态,自回归Transformer输出的文本Token进行分类后解码成对应的输出文本。而输出的视觉Token的embeddings则会作为条件输入给Vision Decoder中解码为输出图像。
之前的All-to-All模型大多直接使用自回归Transformer直接对图像的像素空间进行建模,然后用VAE等模型解码为图像,导致图像质量较差。
为了保证图像质量,Nexus-Gen选择在高维特征空间对图像进行建模,并选择SOTA的扩散模型作为视觉解码器。
相比于处理单一任务的模型,All-to-All模型的潜力在于图像理解、生成、编辑等任务可以相互促进、互相组合
为了完成这一目标,将模型的输入和输出特征空间限定在同一个连续高维特征空间,统一使用Vision Encoder编码图像得到高维特征。对于理解任务,这些特征直接输入模型中作为先验。对于生成任务,这些特征则作为真值指导模型的训练。
预填充自回归策略
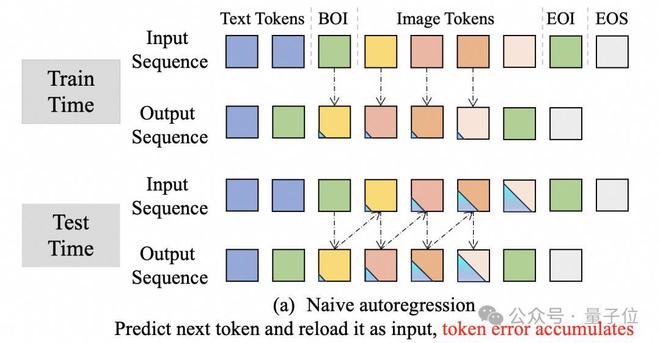
在训练阶段,自回归模型直接使用真值作为输入序列,然后将输入序列左移一位后计算损失函数。在推理阶段,则采用Token-by-Token的自回归:即每预测一个Token,就将其送回输入,预测后续的Token。
团队发现,将这种自回归范式,直接运用在连续特征空间的图像Embedding预测上,会带来比较严重的误差累计问题。
如下图所示,从第一个黄色的图像Token开始,预测的Embedding就存在误差。将带误差的Embedding送回输入中,会导致后续的Embedding预测误差不断增大,最终导致整个图像Token序列预测失败。
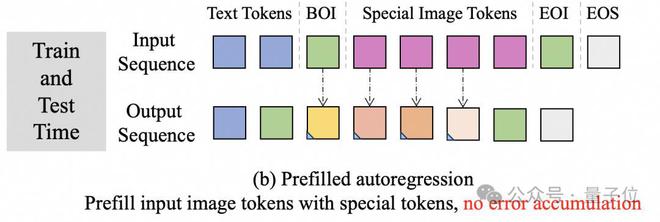
误差累计本质上是由训练和推理行为不一致导致的。为了解决这个问题,魔搭团队提出了预填充自回归的策略,如下图所示。在训练时使用可学习特殊Token填充对应的图像Embedding位置,这样就可以让模型学习直接预测任意位置的图像Token的能力。
在推理阶段,只要预测到图像的起始Token BOI,就直接预填充N个特殊Token到输入序列中。通过这种方式,能够保证训练和推理阶段行为的一致性,从而消除误差累计。
任务构建与训练细节
在Nexus-Gen工作之前,没有看到过在统一的理解、生成和编辑任务上做训练的先例。所以魔搭团队首先从工程上,探索使用类messages格式来定义所有任务的数据格式。如下图所示。

之后,团队从开源社区收集了约25M训练数据并转化为以上统一的格式,其中,图像理解数据6M,图像生成数据12M,图像编辑数据7M。
部分数据使用Qwen-VL-max API进行了重新标注。其中,图像编辑数据包含了团队在ModelScope社区最新开源的,图像编辑数据集系列ImagePulse。
这一系列数据集中,针对GPT-4o不同的图像编辑能力,包含了添加、去除、改变、风格迁移等原子能力而生成的,大约1M高质量样本。
此外后续团队也会将其他在训练过程中使用到的全部数据,都进行开源。
由于Nexus-Gen将图像特征统一在Vision Encoder的高维空间中,因此自回归模型部分和扩散模型部分可以分开训练。
自回归模型使用魔搭开源的SWIFT框架训练,扩散模型则使用了魔搭的DiffSynth-Studio框架训练。下表详细描述了训练过程的细节。
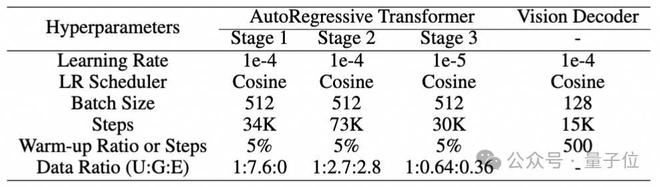
自回归模型采用了三阶段训练策略,前两个阶段逐步将图像生成和图像编辑能力嵌入语言模型中,最后一个阶段则采用少量高质量数据来提升模型生图质量。
扩散模型的训练目标是将输入条件由原本文本输入调整为图像Embedding输入,采用单阶段训练策略。
Nexus-Gen 功能展示
Nexus同时具备图像理解、生成和编辑能力,以下是每个能力的可视化案例。
图像理解

图像生成

图像编辑

未来展望
在模型融合训练、图像Token数量提升、ScaleUp数据集和模型大小等等方面,Nexus-Gen依然存在着大量的优化潜力,目前ModelScope团队在这些不同方向,还在进行更深入的探索。
Nexus-Gen的诞生,验证了从SOTA的MLLMs和扩散模型出发,来对齐以GPT-4o为代表的闭源SOTA的可能性。其效果与GPT-4o具备许多共同点,比如图像编辑会导致原图部分变化、可以文本润色进行多样化图像生成等;团队也发现了许多OpenAI团队没有揭露的现象,比如图像编辑能力极大受益于图像生成,统一模型使多prompt编辑、故事性编辑成为可能等等。
ModelScope社区会持续将探索过程的模型权重、训练数据以及工程框架全部开源,欢迎社区对Nexus-Gen和All-to-All统一模型的技术未来进行广泛交流。
论文链接:https://arxiv.org/pdf/2504.21356
代码链接:https://github.com/modelscope/Nexus-Gen
模型链接:https://www.modelscope.cn/models/DiffSynth-Studio/Nexus-Gen
数据集(ImagePulse)链接:https://www.modelscope.cn/collections/ImagePulse—-tulvmaidong-7c3b8283a43e40
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/12731.html