
算力砍半,视觉生成任务依然SOTA!
达摩院在ICLR 2025上抛出的DyDiT架构:通过时间步长与空间区域的智能资源分配,将DiT模型的推理算力削减51%,生成速度提升1.73倍,而FID指标几乎无损!
更惊人的是,这一突破仅需3%的微调成本。
该方法通过引入动态化调整机制,可精准削减视觉生成任务中50%的推理算力,有效缓解传统扩散模型的计算冗余问题,相关工作已开源。


算力砍半效果依然SOTA
DiT架构作为当前主流的生成模型框架,有效实现了图像与视频的可控生成,推动生成式AI走向应用爆发。
然而,DiT架构的多步生成策略存在推理效率低、算力冗余等问题,在执行视觉生成任务容易造成极高的算力消耗,限制其往更广泛的场景落地。
业内提出高效采样、特征缓存、模型压缩剪枝等方法尝试解决这一问题,但这些方法均针对静态不变模型,又衍生出潜在的冗余浪费问题。
达摩院(湖畔实验室)、新加坡国立大学、清华大学等联合研究团队在论文《Dynamic Diffusion Transformer》提出了动态架构DyDiT,能够根据时间步长和空间区域自适应调整计算分配,有效缓解视觉生成任务中的算力消耗问题。
具体而言,DyDiT能在简单的时间步长使用较窄的模型宽度,减少计算资源;在空间维度上优先处理含有详细信息的主要对象,减少对背景区域的计算资源分配,提升推理效率与减少计算冗余的同时,保持生成质量。
使用者更可根据自身的资源限制或者部署要求,灵活调整目标的计算量,DyDiT将自动适配模型参数,实现效果与效率的最佳平衡。
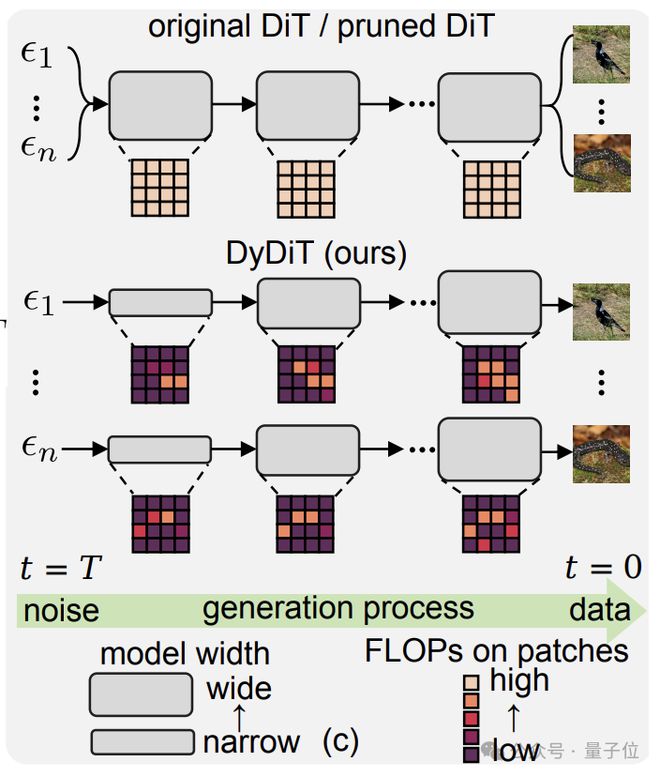
实验结果表明,DyDiT在多个数据集和生成模型下均表现出高稳定性。
仅用不到3%的微调成本,将DiT-XL的浮点运算次数(FLOPs)减少了51%生成速度提高了1.73倍,在ImageNet测得的FID得分与原模型几乎相当(2.27vs2.07)。
据透露,DyDiT相关训练与推理代码已开源,并计划适配到更多的文生图、文生视频模型上,目前基于知名文生图模型FLUX调试的Dy-FLUX也在开源项目上架。
据悉,达摩院今年共有13篇论文被ICLR 2025录用,涵盖了视频生成、自然语言处理、医疗AI、基因智能等领域,其中3篇被选为Spotlight。
论文链接:
https://arxiv.org/abs/2410.03456
技术解读:
https://mp.weixin.qq.com/s/yqYg272vIztflZ6NfX5zJw
开源链接:
https://github.com/alibaba-damo-academy/DyDiT
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/8279.html