
复刻DeepSeek-R1的长思维链推理,大模型强化学习新范式RLIF成热门话题。
UC Berkeley团队共同一作Xuandong Zhao把这项成果称为:

具体来说,新方法完全不需要外部奖励信号或标注数据,只需使用模型自身的置信程度作为内在奖励信号。
与使用外部奖励信号GRPO相比,新方法在数学任务上不需要标准答案也能提升基础模型性能,在代码任务上表现得更好。

几乎同一时间,另外一篇论文《RENT: Reinforcement Learning via Entropy Minimization》也验证了相似的结论。

作者表示两者的主要区别在于使用KL散度和最小化熵衡量自信程度。

Dropbox工程副总裁看后表示:Confidence is all you need。

“自信”驱动的强化学习
长期以来,训练大模型主要依赖两种方式:
要么需要大量人工标注(如ChatGPT的RLHF),要么需要可验证的标准答案(如DeepSeek的RLVR)。
前者成本高昂且可能引入偏见,后者则局限于数学、编程等有明确答案的领域。
那么当AI能力逐渐接近甚至超越人类时,能否让模型仅凭自身产生的内在信号,摆脱对外部监督的依赖?
针对这个问题,UC Berkeley团队提出新训练方法Intuitor,计算模型预测分布与均匀分布之间的KL散度作为“自信程度”。

相当于人类做题时,如果对答案有把握思路也会更清晰,当自信不足的时候往往需要重新思考。
通过优化这个内在信号,INTUITOR鼓励模型生成它自己”更有把握”的回答,也能促使模型生成更结构化的推理过程。
在实验中,1.5B和3B的小模型也涌现出与DeepSeek-R1类似的长思维链推理行为。

论文还指出,内在奖励信号还获得一个额外的好处:从机制上降低了“奖励黑客”的风险。
传统外部奖励信号的强化学习容易被“钻空子”,如模型可能生成语法正确但逻辑错误的代码来匹配测试用例,或在数学题中直接背答案而非推理。
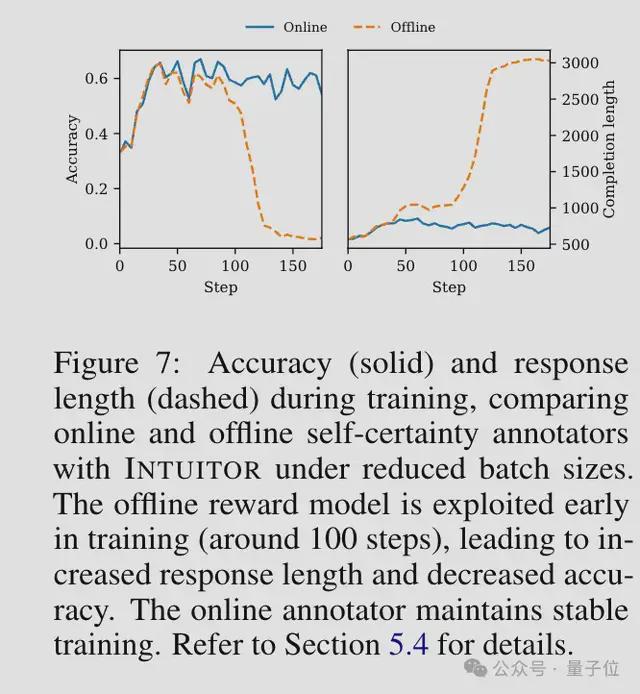
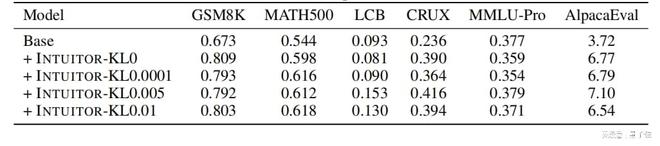
在INTUITOR中,团队发现如果使用离线学习,在训练约100步的时候模型也学会了作弊:在回答中附加一个已经解决的简单问题来提高自信度分数。
但使用在线学习就可以避免这个问题,评估标准随着模型能力一起进化,作弊策略变得无效。
实验结果:不仅会做题,还会举一反三
团队首先实证研究了INTUITOR框架对LLMs数学推理能力的提升。
实验选取Qwen2.5-1.5B/3B作为基础模型,使用自我确定度作为唯一的奖励信号,并将其分别置于INTUITOR和两个基线方法(GRPO、GRPO-PV)在MATH数据集的预训练中。
使用对话提示,每次处理128道题目并各生成7个候选解决方案,KL惩罚系数设置为0.005。
在数学推理、代码生成、指令遵循的基准测试中进行性能评估,结果如图所示:
实验表明,在通过INTUITOR进行微调后,Qwen2.5-1.5B从最初只会输出重复的无意义内容且对话任务得分均低于10%,转变为无效输出大幅减少、响应长度有效增加。
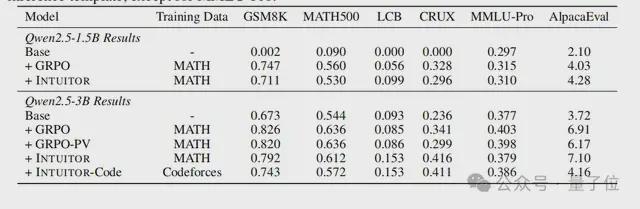
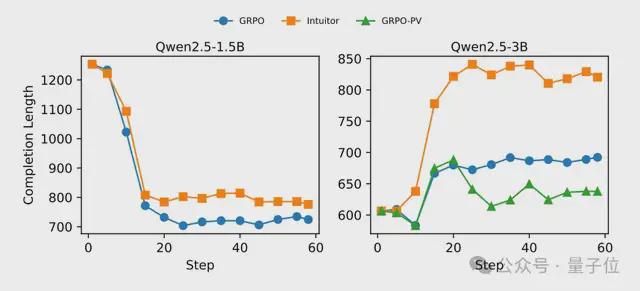
在结构化推理能力上,团队还发现INTUITOR早期学习速度更快,如Qwen2.5-3B在GSM8K基准测试上INTUITOR(0.811)始终优于GRPO(0.758)。
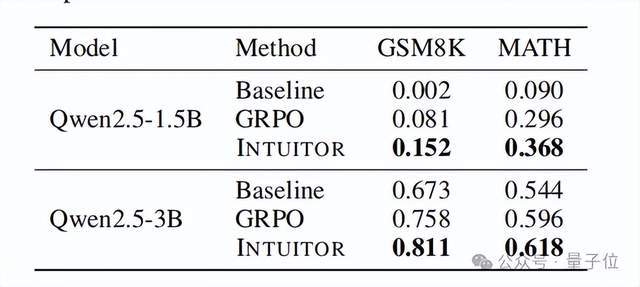
此外,INTUITOR在多任务泛化上也表现优秀,例如当Qwen2.5-3B在代码生成任务上,虽然相对滞后但持续增长,最终性能比GRPO高8%,相对提升65%。

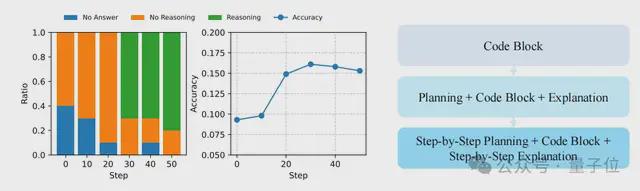
同时团队还观察到,在进行长链推理时,INTUITOR模型在生成完整代码前,都会添加自然语言推理(如“为解决X问题,需先执行Y步骤”),据推测也许这就是INTUITOR能够在测试中始终表现出色的原因之一。
它的演进过程大概可以描述为三个阶段:
- 模型学会生成代码,实现准确率提升和无效响应减少。
- 进行代码前推理以促进自我理解。
- 逐步细化生成带详细推理的有效代码。
为了评估自我确定度作为奖励的鲁棒性,研究人员还将离线自我确定度(来自固定基础模型的奖励)与在线自我确定度(来自不断进化的策略模型的奖励)进行了比较。
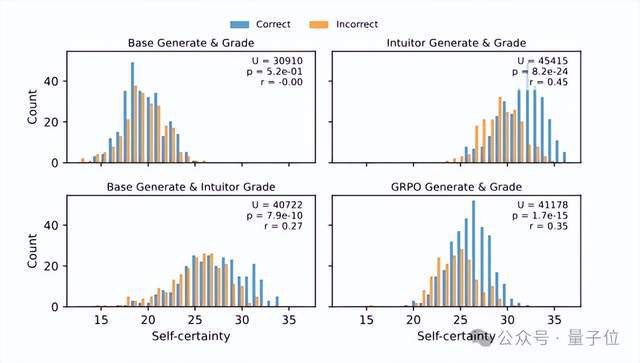
另外为进一步评估自我确定度作为奖励信号的质量,研究人员还分析了模型在MATH500响应中生成的自我确定度分数分布。
值得注意的是,INTUITOR模型对正确答案的self-certainty显着更高,而GRPO虽提升了模型自评能力,但区分度明显低于INTUITOR。
由于受计算资源限制,实验只在相对较小的无监督语料库上进行训练,未来可在更大规模的基础模型和更多样化的真实世界数据集上进一步研究INTUITOR的优势。
团队介绍
本项研究来自UC Berkeley的Sergey Levine、宋晓东团队,作者一共有五位,分别是第一作者博士后研究员Xuandong Zhao、共同一作本科生Zhewei Kang、来自耶鲁大学的Aosong Feng,以及Sergey Levine和Dawn Song。

2019年,Xuandong Zhao从浙江大学毕业后,就进入了加州大学圣塔芭芭拉分校攻读计算机科学博士学位,期间还曾在阿里巴巴、Microsoft和Google等公司实习。
自2024年他进入UC Berkeley后,除本次的新成果外,至今一共还发表过十多篇论文,并先后被ICLR 2025、ICML 2025等接收。

另外在今年2月,Xuandong Zhao和Zhewei Kang还合作发表了一篇论文,描述了基于自我确定性的LLMs推理能力提升新策略Best-of-N,可以看作是本篇论文的一次先验尝试。

论文链接:https://arxiv.org/abs/2505.19590
代码链接:https://github.com/sunblaze-ucb/Intuitor
参考链接:
[1]https://x.com/joshclemm/status/1927400772817285264
[2]https://x.com/xuandongzhao/status/1927270931874910259
[3]https://x.com/xuandongzhao/status/192778163679341780
[4]https://arxiv.org/abs/2502.18581
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/17616.html