
在推荐、广告场景,如何利用好大模型的能力?这是个很有挑战的命题。
背后主要有两个核心难点:
1)LLM虽然具备丰富的世界知识和推理能力,但缺乏电商领域的专业知识,在直接应用中往往表现欠佳。
2)LLM的交互方式多为文本,而直接将用户历史行为以文本格式描述会导致输入信息冗长、信息密度低等问题,对建模和推理都造成了困扰。
为了解决以上问题,阿里妈妈提出了一种世界知识大模型URM,通过知识注入和信息对齐,让LLM成为兼顾世界知识和电商知识的专家。相比于传统的推荐模型,URM通过对用户兴趣的全面理解,可实现基于推理认知能力的用户兴趣推荐。
为了在低时延、高QPS要求的实际系统中上线应用,阿里妈妈技术团队设计了一套面向用户行为动态捕捉的异步推理链路。
目前,URM已经在阿里妈妈展示广告场景上线,在商家的投放效果和消费者的购物体验等指标上均带来了显着提升。
以下面这个例子为例,一个对嵌入式家电、收纳用品有过历史行为的用户,系统推测用户在关注装修且处于硬装的早期阶段,且根据点击商品推断用户比较注重生活品质,因此推荐了一些全屋定制类产品以及高品质的家电。


在传统推荐任务之外,通过特定的文字引导,URM可结合用户的历史兴趣产出更适合当前情境的结果。通过用户行为我们推测用户是一位男童的母亲,并且关注过儿童的新年衣服和女士牛仔裤。
当引导词增加新年时,推荐结果以儿童新年服装为主,而传统任务下系统会倾向于推荐用户近期浏览较多的女式牛仔裤。

本届互联网技术领域国际顶级学术会议-国际万维网大会(International World Wide Web Conference,简称WWW)于4月28日在悉尼召开。
会议期间,淘天集团的阿里妈妈共同主持一个计算广告算法技术相关的Tutorial(讲座),内容为介绍计算广告领域的技术发展脉络,以及阿里妈妈在该领域的最新技术突破——
阿里妈妈LMA2广告大模型系列中的URM(Universal Recommendation Model)世界知识大模型,首次重磅亮相。
世界知识大模型URM
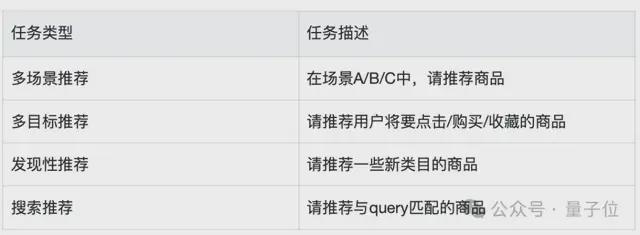
个性化推荐在人们的日常生活中出现频率越来越高。为了满足用户的多样化需求,推荐系统中的任务定义也更加多元化,如多场景推荐、多目标推荐、发现性推荐等等。
参考LLM在自然语言处理领域的巨大成功,阿里妈妈技术团队希望基于LLM构建电商领域的世界知识大模型,使得它能同时具备LLM的世界知识和电商领域的专业知识,且能够轻松应对上述全部任务。
基于此,阿里妈妈技术团队提出了世界知识大模型Universal Recommendation Model(以下称URM),以预训练的LLM为基座,将多任务设计融入Prompt设计中,通过ID表征的知识注入和电商领域的任务对齐,实现对用户历史兴趣的理解和推理并最终推荐出符合用户兴趣的结果。
以下将从任务定义、整体架构、离线实验三方面详细展开。
任务定义
参考LLM的训练范式,在URM中,阿里妈妈技术团队利用文本来定义不同的推荐任务。
考虑到推荐场景用户行为的重要性和丰富性,为了充分刻画用户的历史行为,避免商品标题的冗长和低密度,URM将商品ID作为一种特殊的token注入文本描述,实现用户行为序列的高效表达。
考虑到工业场景落地的效率,URM直接生成商品ID,同时在输出结果中保留了文本,在对齐电商任务的同时保留LLM本身的知识。

多任务会通过输入中的任务描述体现,部分示例参考下表。
整体架构
为了保留LLM的预训练知识,阿里妈妈技术团队保留多层Transformer结构不变,对输入层和输出层的结构进行修改,如下图所示。
输入端,输入序列由用户行为中的商品ID、任务提示中的文本token以及[UM]、[LM]等特定查询符组成。商品ID通过分布式商品Embedding模块映射为商品Embedding,其他文本映射为Token Embedding,商品 Embedding或Token Embedding与Postion Embedding相加后输入到 LLM的主干网络(对于使用RoPE的模型而言则不存在显式的Position Embedding)。
输出端,为了避免产出推荐结果和推理文本相互干扰,阿里妈妈技术团队在输入中增加了[UM]和[LM] 2种特殊字符来表示当前应该输出用户表征还是开始生成文本。与[UM]符号对应的输出通过用户建模头hUM映射到用户表示空间,用于候选商品的生成;与[LM]符号及其后续符号对应的输出通过语言模型头hLM映射到文本空间,用于文本token的生成。
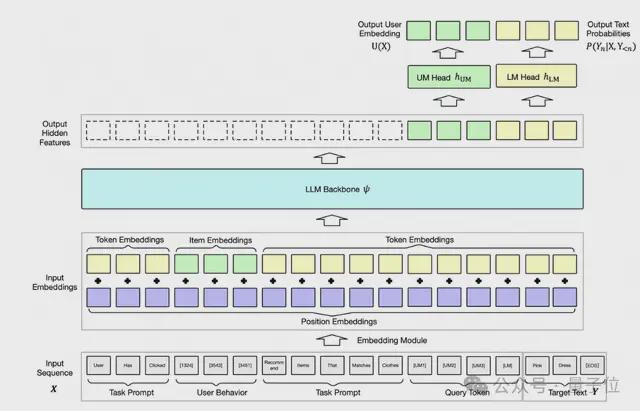
△URM整体架构
URM架构区别于传统LLM主要有2个模块,1是商品多模态融合的表征方式,2是兼顾效果和效率的Sequence-In-Set-Out生成方式。
以下会分别介绍这两部分。最后介绍URM的训练方式。
商品多模态融合表征。
在传统推荐模型中,ID表征是面向特定任务的数据分布学习的,代表了商品间的相似关系,压缩了电商领域的协同信息。而LLM中通常采用文本、图像等语义表征,描述内容信息间的相似性。
为了提升LLM对电商信号的理解,同时保留LLM的知识,表征层设计了 ID表征和语义表征的融合模块来表达商品,并通过可学习MLP层实现ID 表征和文本、图像等语义表征的对齐。
同时,这套融合表征的设计具备较强的可扩展性,如语义ID等token均可作为新增模态引入,来不断强化商品的表达能力。
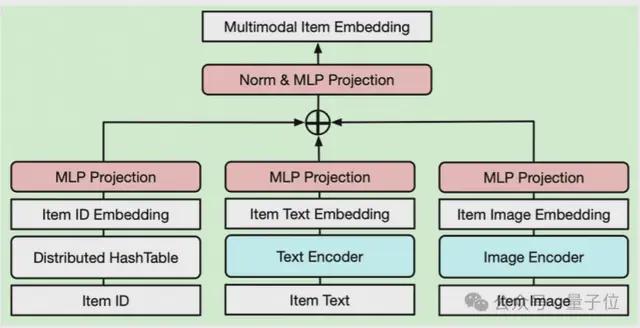
△商品融合表征,输入ID/Text/Image表征固定,MLP层可学习
Seqence-In-Set-Out生成方式
推荐的目标是从一个千万级别的候选库中找到曝光/点击概率最大的K个商品,它和语言模型LM从十万规模的词表空间中生成语言概率最大的 Token,是类似的问题。
因此若不考虑计算成本,可以通过下述方式获得结果:
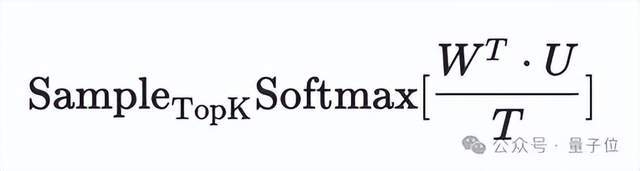
其中U是大语言模型生成的用户表征,对应LM中的隐藏层特征,W是所有商品的融合表征,对应LLM中的最后一层的参数。考虑到工业界的落地可行性,阿里妈妈技术团队使用生成的用户表征和候选商品表征的内积作为分数并采样分数TopK的商品作为最终生成的结果。
在这种内积计算的范式下,模型的表达能力相对受限,对用户和商品的建模能力较差且推荐集合的多样性也会较差,难以发挥大语言模型的优势。函数逼近理论的一个结论是,特征的多个内积的线性组合可以逼近任意复杂的函数。因此通过增加[UM]token的数量使URM在一次前向过程中并行生成多个用户表征U=(U1,……,UH),最终用户和商品之间的打分为
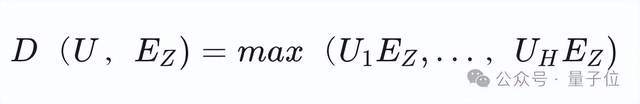
这种Set-Out的多输出方式不仅能够保持仅需一次前向计算的相同推理效率,而且随token数上涨召回指标显着提升,同时解决了单一用户表征兴趣覆盖度有限的问题。

△不同[UM] Token输出的可视化
训练方式
整体训练损失包括商品推荐任务损失和文本生成任务损失。
输出序列表示为

目标文本表示为

目标商品表示为
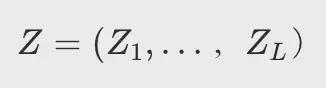
商品推荐任务通过噪声对比估计(NCE)损失来优化:
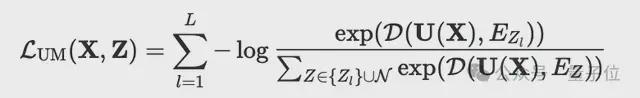
其中用户建模头hUM输出的用户表征:

在每个批次中,负样本N是从商品候选中基于其出现频率采样得到的。
文本生成任务可以通过目标文本序列的负对数似然来优化:
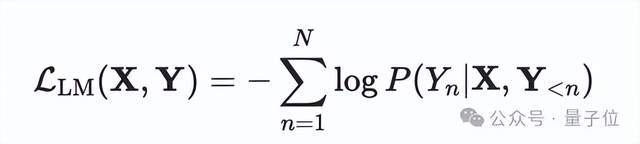
其中P= softmax(hLM(ψ(⋅))是由语言模型头hLM输出的概率。
最终的训练目标是:
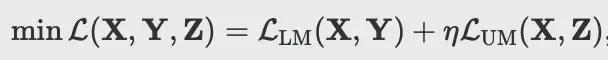
其中η是权衡超参数。考虑到URM对LLM的输入和输出层进行了显着修改,阿里妈妈技术团队采用完整参数的有监督微调(SFT),仅冻结商品的原始表征。
离线实验
URM使用多任务融合数据集训练,并在生产数据集上取得了平均11.0%的Recall提升,在6个子任务(共9个任务)中都超越了线上使用 Target-Attention结构的传统推荐模型。
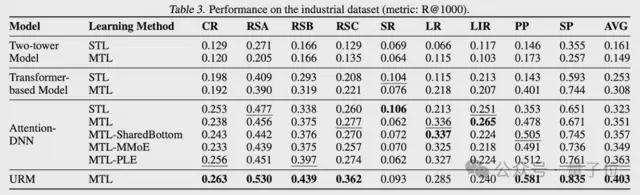
△URM在多任务上的表现 vs 传统模型
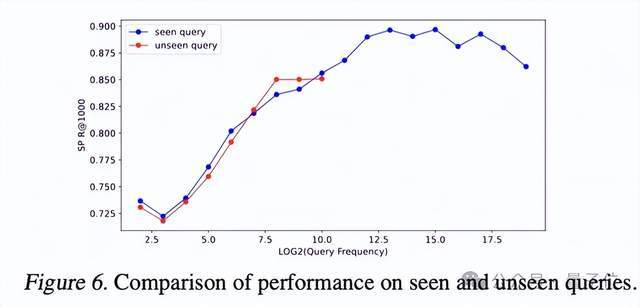
进一步的消融实验,验证了表征融合模块的有效性,也验证了随UM token数量上涨召回Recall呈显着上涨。Figure6验证了URM仍具有良好的文本理解能力和泛化能力,对已知的query文本和未知的query都有良好的推荐表现。
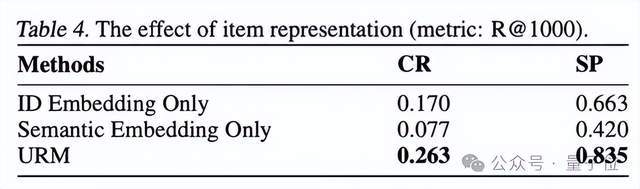
△商品多模态表征融合模块消融实验

△UM头输出数量对效果的影响
高QPS低时延约束下的落地方案
考虑到LLM的推理时延较长,无法满足在线请求的时延约束,阿里妈妈技术团队建设了一套异步推理的大模型召回链路。
如下图所示,在用户有淘系行为时异步触发URM推理,并将结果做持久化存储,供在线召回阶段读取使用。
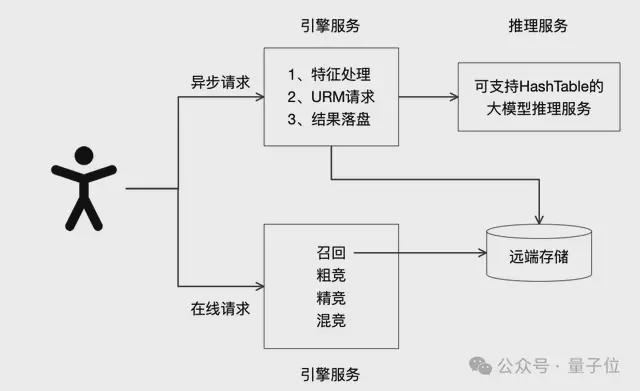
在模型推理服务上,由于URM在商品多模态融合表征模块和User表征检索方式的改造,需要在LLM推理中增加HashTable支持,并支持推理表征的向量检索。
为了进一步提升资源利用率,阿里妈妈技术团队实现了多instance在同一容器的部署,将URM推理的并发qps提升200%。
结语
本文主要介绍了阿里妈妈LMA 2广告大模型系列中的世界知识大模型URM在建模和落地方面的思考和进展。通过结合大模型的通用知识和电商领域的专家知识,URM能够更加精准地预测用户的潜在兴趣和购物需求,为商家和消费者提供更优质的服务。
更多URM的细节欢迎关注后续“阿里妈妈技术”的公众号文章或参考论文。
论文链接:
https://arxiv.org/pdf/2502.03041
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/9880.html